폐암 데이터 이진 분류
2024. 6. 26. 12:42ㆍDeep Learning
✅ 활성화 함수 종류

✅ 활성화 함수
-> 사람의 신경망에서 역치(문턱값)를 구현하기 위해 도입된 함수



📌 기본적인 뉴런의 구조는 선형 회귀
- 활성화 함수를 거치지 않은 뉴런에서 나오는 값은 연속된 실수 값


📌 계단함수 - 시그모이드 함수 비교
- 어제 술을 마신 사람이 등원을 한다 / 안한다를 판단하는 모델
- 1. 계단함수 -> 안나간다
- 나간다
- 안나간다
- 나간다
- 안나간다
- 안나간다
- 2. 시그모이드 함수
- (나감 : 안나감)
- 술이랑 상관 없다 나가야지 0.9 0.1 나감
- 술 마셔서 힘들지만 나가자 0.7 0.3 나감
- 컨디션 난조 무서운데... 0.4 0.6 안나감
- 공부보다 건강이 우선! 0.3 0.7 안나감
- 아 귀찮아! 땡땡이 0.3 0.7 안나감
- -- 확률 정보의 총합 -- 2.6 2.4 -> 나왔다

✅ 목표 설정
- 폐암 데이터를 활용해서 이진 분류 신경망 구현
- 이진 분류 개념을 이해한다.
# 드라이브 마운트
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/MyDrive/Colab Notebooks/Deep Learning
!ls
# 필요한 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 데이터 불러오기
data = pd.read_csv('data/ThoraricSurgery.csv', header=None)
data
# 현재 데이터는 컬럼명이 별도로 존재하지 않는다.
# 이 상태로 데이터를 불러오면 첫번째 행이 컬럼 명으로 불러와진다.
# header 옵션을 사용해서 새로 불러와보자
# header : 데이터를 불러오면서 컬럼명을 설정해주는 키워드
# (None)으로 설정한 경우 : 인덱스 번호가 컬럼명으로 출력된다.
# 데이터 정보 : 0 ~ 16 컬럼 -> 속성(특성) : 종양 유형, 폐활량, 고통정도 등등
# 17번 컬럼 : 정답 클래스(수술 후 생존 결과) - 0(사망) / 1(생존)
data.info() # 결측치 없다. 정수 / 실수
✅ 데이터 분리
- 문제 데이터 / 정답 데이터 분리
- 훈련 데이터와 평가 데이터 분리
# 1. 문제 데이터와 정답 데이터로 분리 (iloc)
X = data.iloc[:, :-1]
y = data[17]# 데이터 체크(shape)
X.shape, y.shape
# 훈련 셋과 평가 셋으로 분리(30%, 30)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=30)# 데이터 체크(shape)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
✅ 신경망 구축
- 신경망 구조 설계
- 학습 / 평가 방법 설정
- 학습 + 시각화
- 모델 평가
# 재료 import
# 뼈대 구성 재료
from tensorflow.keras.models import Sequential
# 층 구성 재료 - Dense
from tensorflow.keras.layers import Dense# 모델 구축 시작
# 뼈대 설정
model = Sequential()
# 입력층 설정
# 뉴런의 갯수 = 10 / 데이터 입력 특성 갯수 = ?(체크 잘할 것) / 시그모이드 함수
model.add(Dense(10, input_dim=17, activation='sigmoid'))
# 중간층 설정
# 뉴런의 갯수 = 6 / 시그모이드 함수
model.add(Dense(6, activation='sigmoid'))
# 뉴런의 갯수 = 4 / 시그모이드 함수
model.add(Dense(4, activation='sigmoid'))
# 출력층 설정
# 뉴런의 갯수 = 1 / 시그모이드 함수
model.add(Dense(1, activation='sigmoid'))
# 현재 우리가 진행하는 분석 방법은 어떤 방법인가? -> 분류 -> 이진분류
# 출력층의 구조는 우리가 에측하는 분석 방법에 따라 구조가 달라진다.
# 이진 분류에서는 활성화 함수 sigmoid / 뉴런의 갯수 1
# 회귀 분석에서는 활성화 함수 생략 / 뉴런의 갯수 1
# 모델 요약
model.summary()
✅ 분석 방법에 따른 출력층 구조 및 손실함수 확인해보기
- 📌 1. 회귀 분석
- 출력층 뉴런의 갯수 : 1
- 활성화 함수 : 생략 가능
- 손실 함수 : mse(평균 제곱 오차)
- 📌 2. 이진 분류
- 출력층 뉴런의 갯수 : 1
- 활성화 함수 : sigmoid
- 손실함수 : binary_crossentropy
- 📌 3. 다중 분류
- 출력층의 뉴런의 갯수 : 클래스의 종류 갯수(원핫 인코딩한 정답 데이터의 컬럼 개수)
- 활성화 함수 : softmax
- 손실 함수 : categorical_crossentropy
model.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy'])
✅ activation(활성화 함수) : 자극에 대한 반응 여부를 결정
- 회귀 : linear -> 신경망에서 도출된 수치값(결과값)을 그대로 예측값으로 사용
- 분류 :
- 딥러닝은 선형 모델 기반이다.
- 도출된 수치값은 연속된 실수 -> 분류 예측 어려움
- 이를 해결하기 위해 분류할 수 있는 형태로 변경(활성화 함수 도입)
- 이진 분류 문제에서는 출력층에 활성화 함수를 sigmoid 함수로 사용한다. (0 / 1 분류, 0.5라는 기준 값을 가지고 높은지 낮은지 확률 정보를 바탕으로 최종 출력을 결정)
# 3. 모델 학습
h = model.fit(X_train, y_train, epochs=100)
# 모델 학습 시각화
plt.plot(range(1, 101), h.history['accuracy'])
plt.show()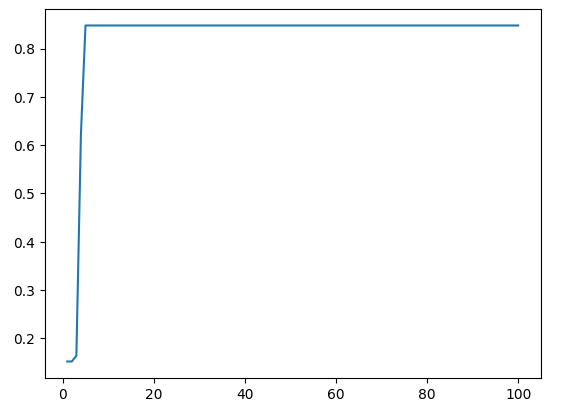
# 모델 평가
model.evaluate(X_test, y_test)
# 모델 예측
pre = model.predict(X_test)
pre
# y_test의 고유값과 갯수를 파악해보자
np.unique(y_test, return_counts=True)
# 혼동 행렬로 예측 결과를 표시해보자
pre = pre > 0.5
from sklearn.metrics import confusion_matrix, classification_report # classification_report : 분류 평가 보고서
cm = confusion_matrix(y_test, pre)
display(cm)
cm_df = pd.DataFrame(cm, index=['실제 0', '실제 1'], columns=['예측 0', '예측 1'])
cm_df
# 실제 사망인 것을 사망으로 예측 성공한 경우 : 121(tn)
# 실제 사망이 아닌 것을 사망으로 예측한 경우 : 20(fn)



✅ 문제 유형에 따른 활성화 함수, 손실 함수

'Deep Learning' 카테고리의 다른 글
| 모델저장 학습중단 과적합 (0) | 2024.07.01 |
|---|---|
| mlp_활성화 함수, 최적화 함수 비교 패션 데이터 다중 분류 (0) | 2024.06.28 |
| iris 데이터 다중 분류 실습 (0) | 2024.06.27 |
| 학생 수학 성적 예측 (0) | 2024.06.26 |
| 딥러닝 기초 (0) | 2024.06.20 |