모델저장 학습중단 과적합
2024. 7. 1. 22:38ㆍDeep Learning
✅ 학습 목표
- 베스트 모델 저장하기 / 불러오기
- 학습 중단 기능
- 과적합 방지 - Dropout
✅ 베스트 모델 저장하기 / 학습 중단
- 📌 손글씨 이미지 데이터셋
- 훈련 데이터 6만개, 테스트 데이터 1만개
- 0 ~ 9까지 숫자 이미지에 대한 라벨링
from tensorflow.keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train.shape, X_test.shape
- 📌 데이터 확인
import matplotlib.pyplot as plt
print(y_train[10])
plt.imshow(X_train[10], cmap='gray')
plt.show()
- 📌 이미지(2차원) -> Dense(1차원) 변환
X_train = X_train.reshape(-1, 28*28)
X_test = X_test.reshape(-1, 28*28)
X_train.shape, X_test.shape
- 📌 스케일링 : 0 ~ 255 -> 0.0 ~ 1.0
X_train = X_train / 255.0
X_test = X_test / 255.0X_train
- 📌 라벨 데이터는 원핫 인코딩(다진 분류)
from keras.utils import to_categorical
y_train_en = to_categorical(y_train)
y_test_en = to_categorical(y_test)
y_train_en.shape, y_test_en.shape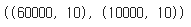
- 📌 신경망 설계
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model1 = Sequential()
# input_dim : 입력 데이터의 크기
model1.add(Dense(512, activation='relu', input_dim=28*28))
# 10 -> 라벨 데이터의 크기
model1.add(Dense(10, activation='softmax'))
model1.summary()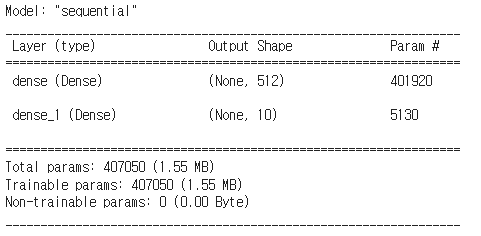
model1.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) # categorical_crossentropy -> 다중분류# validation_data : 테스트 데이터가 있는 경우
# validation_split : 테스트 데이터가 없는 경우 -> 훈련 데이터에서 비율만큼 가져온다
h1 = model1.fit(X_train, y_train_en, epochs=5, batch_size=128, validation_data=(X_test, y_test_en))
- 📌 베스트 모델 저장, 학습 중단 설정
- 베스트 모델 : 학습 중에서 설정한 기준 값이 가장 좋은 모델을 저장 (ModelCheckPoint())
- 학습 중단 : 학습 중에 설정한 기준 값이 만족하는 경우에 학습을 중지 시키는 기능 (EaryStopping())
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/MyDrive/Colab Notebooks/Deep Learning
from keras.callbacks import ModelCheckpoint, EarlyStopping
import os
# 모델을 저장할 폴더
model_dir = './model/'
# 만약 해당 폴더가 없으면 생성
if not os.path.exists(model_dir):
os.mkdir(model_dir)
# {epoch:02d} : epoch 변수의 값을 2자리 정수로 설정
# {loss:.4f} : loss 변수의 값을 소수점 4째 자리까지로 설정
# {val_loss:.4f} : val_loss 변수의 값을 소수점 4째 자리까지로 설정
# 파일명 예시 : model1_20_0.526_0.406.hdf5
file_name = model_dir + "model1_{epoch:02d}_{loss:.4f}_{val_loss:.4f}.hdf5"
# 베스트 모델 저장 설정
# monitor : 베스트 모델을 결정하는 기준값
# save_best_only=True : monitor에서 설정한 기준값이 더 나아지는 경우에만 저장
mc = ModelCheckpoint(file_name, monitor='val_loss', save_best_only=True) # val_loss -> 과대적합이 안걸리는 가장 바람직한 방법
# 학습 중단 기능 : 얼마만큼 학습 횟수를 설정할지 알 수 없기 때문에 학습이 더 나아지지 않는 경우에 자동으로 중지
# monitor : 학습 중단을 결정하는 기준값 (가능하면 ModelCheckpoint와 동일한 값을 권장)
# patience : 학습이 더 나아지지 않더라도 기다려주는 횟수
es = EarlyStopping(monitor='val_loss', patience=5)
# validation_data : 테스트 데이터가 있는 경우
# validation_split : 테스트 데이터가 없는 경우 -> 훈련 데이터에서 비율만큼 가져온다
# callbacks : 반복 시 마다 호출되어 실행
h1 = model1.fit(X_train, y_train_en, epochs=20, batch_size=128, validation_data=(X_test, y_test_en), callbacks=[mc, es])

import matplotlib.pyplot as plt
plt.plot(h1.history['accuracy'], label="train")
plt.plot(h1.history['val_accuracy'], label="test")
plt.legend()
plt.show()
plt.plot(h1.history['loss'], label="train")
plt.plot(h1.history['val_loss'], label="test")
plt.legend()
plt.show()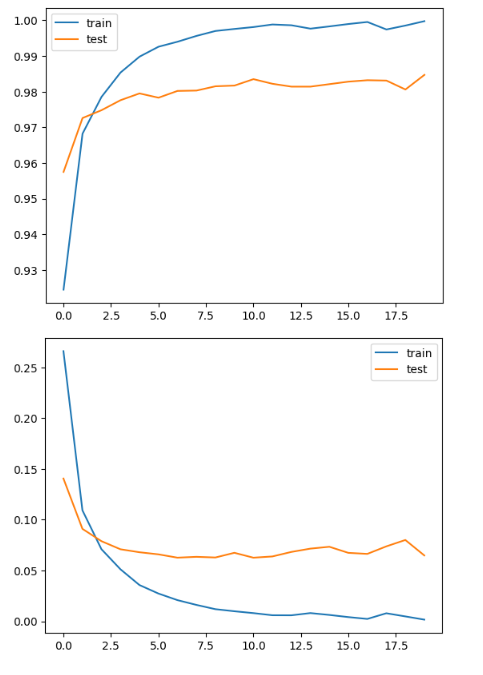
- 📌 모델 불러오기
from keras.models import load_model
# model_dir = './model/'
file_name = model_dir + "modelmodel1_01_0.0004_0.0666.hdf5"
model2 = load_model(file_name)
model2.evaluate(X_train, y_train_en)
model2.evaluate(X_test, y_test_en)
- 📌 예측하기
idx = 200
pred = model2.predict(X_test[idx:idx+1])
print(pred)
# 가장 큰 값을 갖는 인덱스를 반환
print(pred.argmax())
# 실제 값
print(y_test[idx])
import matplotlib.pyplot as plt
plt.imshow(X_test[idx].reshape(28, 28), cmap='gray')
plt.show()
# 잘못 예측한 데이터 출력
pred = model2.predict(X_test)
co = 0
failed = 0
for i in pred :
if pred[co].argmax() != y_test[co] :
failed += 1
print(co)
co += 1
print("잘못 예측한 데이터 수 : ", failed)
- 📌 내 손글씨 인식하기
- 모델을 만들 때 수행했던 전처리를 그대로 해주어야 한다










# 이미지 불러오기
import PIL.Image as pimg
import numpy as np
import matplotlib.pyplot as plt
img = pimg.open('./data/2.png').convert('L')
# convert('L') : 컬러 -> 흑백 이미지로 변환
plt.imshow(img, cmap = "gray")
plt.show()
- 📌 데이터의 형태 : (1,784)
- 📌 데이터 값 : 0.0 ~ 1.0
img = np.array(img)
img.shape
testimg = img.reshape(-1, 28 * 28)
testimg.shape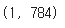
testimg = testimg / 255.0
testimg
pred = model2.predict(testimg)
print(pred)
print(pred.argmax())
- 📌 과적합 방지
- Dropout()
- 각 층의 퍼셉트론의 수를 설정한 비율만큼 제한 -> 각 반복마다 적용되는 퍼셉트론은 랜덤으로 선택
- 제한 비율을 0.5 이하로 설정 -> 0.5 이상이면 해당 층의 신경망이 가지는 특성이 효과적으로 적용되지 못하기 때문
- 퍼셉트론의 수가 감소 -> 파라미터의 수가 감소 -> 복잡도 감소 -> 과적합 감소
- Dropout()
import pandas as pd
# 특성 60개로 구성
# 암석에 음파를 쏴서 반사되는 파를 확인해서 금속을 탐지
# header = None : 원본 파일에 열 이름이 없는 데이터
sonar = pd.read_csv('./data/sonar.csv', header = None)
sonar.head()
# 라벨 데이터 확인
sonar[60].value_counts()
import tensorflow as tf
# 다른 컴퓨터에서 작업을 하더라도 w와 b 값이 같은 값으로 초기화
# 모델을 개선했을 때 모델의 성능을 판별
seed = 0
tf.random.set_seed(seed)
np.random.seed(seed)# 특성 / 라벨 데이터 분리
X_train = sonar.iloc[:, :60]
y_train = sonar.iloc[:, 60]
X_train.shape, y_train.shape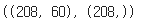
- 📌 라벨 데이터 인코딩
- M, R의 문자 형태로 되어 있는 라벨을 숫자로 변환 -> 라벨 인코딩
- 0부터 숫자가 알파벳 순으로 부여
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
encoder.fit(y_train)
y_train_en = encoder.transform(y_train)y_train_en
# M -> 0, R -> 1
# 훈련, 검증 데이터
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train_en, test_size=0.2, random_state=seed)
X_train.shape, y_train.shape, X_val.shape, y_val.shape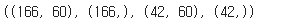
- 📌 모델 설계
- 📌 컴파일
- 📌 학습 (베스트 모델 저장, 학습 중단)
- 📌 저장된 모델 불러오기
- 📌 불러온 모델로 예측하기 (X_test)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
model3 = Sequential()
# 입력층
model3.add(Dense(512, activation='relu', input_dim=60))
# 은닉층
model3.add(Dense(256, activation='relu'))
model3.add(Dense(128, activation='relu'))
model3.add(Dense(64, activation='relu'))
# 인코딩 : 퍼셉트론 수 (특성 수)를 감소 시켜가는 방식 (압축, 정보 요약, 중요 특성 추출 / 선택)
# 디코딩 : 퍼셉트론 수 (특성 수)를 증가 시켜가는 방식 (복원)
# 출력층
# 원핫 인코딩 하지 않았음 -> 퍼셉트론 수 1, 활성화 함수 sigmoid
# 원핫 인코딩 했다면 -> 퍼셉트론 수 2, 활성화 함수 softmax
model3.add(Dense(1, activation='sigmoid'))
model3.summary()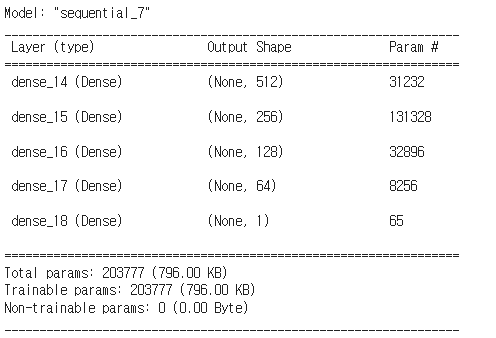
model3.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])from keras.callbacks import ModelCheckpoint, EarlyStopping
mc = ModelCheckpoint('./model/model2_{epoch:02d}_{loss:.4f}_{val_loss:.4f}.hdf5', monitor='val_loss', save_best_only=True)
es = EarlyStopping(monitor='val_loss', patience=10)# h2 = model3.fit(X_train, y_train, epochs=200, batch_size=16, validation_data=(X_val, y_val), callbacks=[mc, es])
h2 = model3.fit(X_train, y_train, epochs=200, batch_size=16, validation_data=(X_val, y_val))
import matplotlib.pyplot as plt
plt.plot(h2.history['accuracy'], label="train")
plt.plot(h2.history['val_accuracy'], label="test")
plt.legend()
plt.show()
plt.plot(h2.history['loss'], label="train")
plt.plot(h2.history['val_loss'], label="test")
plt.legend()
plt.show()
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
model4 = Sequential()
model4.add(Dense(512, activation='relu', input_dim=60))
model4.add(Dropout(0.3))
model4.add(Dense(256, activation='relu'))
model4.add(Dropout(0.3))
model4.add(Dense(128, activation='relu'))
model4.add(Dropout(0.3))
model4.add(Dense(64, activation='relu'))
model4.add(Dense(1, activation='sigmoid'))
model4.summary()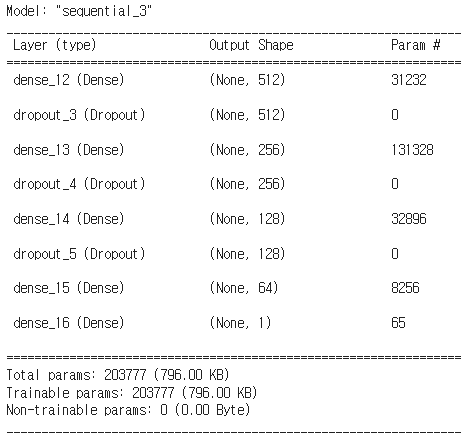
model4.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])h3 = model4.fit(X_train, y_train, epochs=200, batch_size=16, validation_data=(X_val, y_val))
import matplotlib.pyplot as plt
plt.plot(h3.history['accuracy'], label="train")
plt.plot(h3.history['val_accuracy'], label="test")
plt.legend()
plt.show()
plt.plot(h3.history['loss'], label="train")
plt.plot(h3.history['val_loss'], label="test")
plt.legend()
plt.show()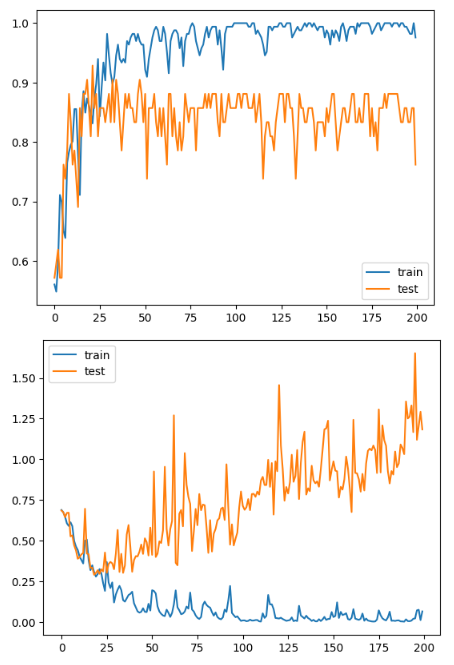
'Deep Learning' 카테고리의 다른 글
| CNN 개_고양이_이진분류 실습(데이터 만들기) (0) | 2024.07.08 |
|---|---|
| CNN(Convolutional Neural Network) (0) | 2024.07.05 |
| mlp_활성화 함수, 최적화 함수 비교 패션 데이터 다중 분류 (0) | 2024.06.28 |
| iris 데이터 다중 분류 실습 (0) | 2024.06.27 |
| 폐암 데이터 이진 분류 (0) | 2024.06.26 |