딥러닝 기초
2024. 6. 20. 18:00ㆍDeep Learning
✅ Deep Learning

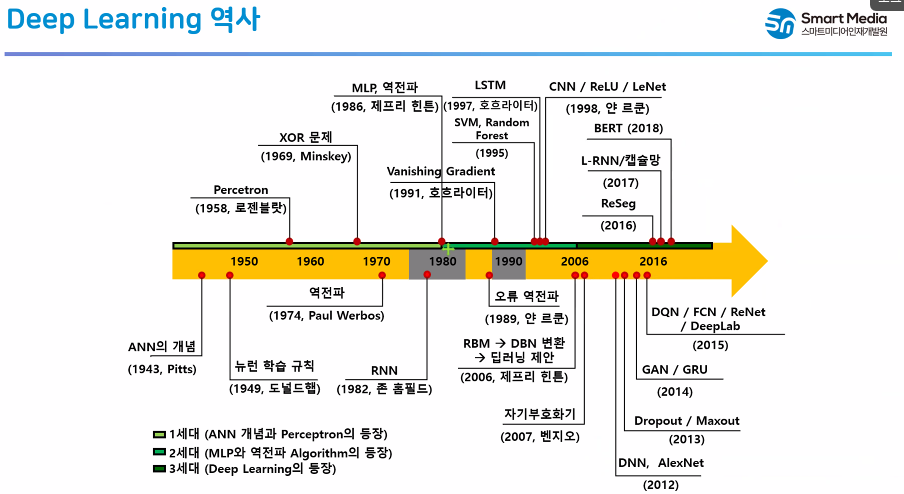
✅ Deep Learning 역사

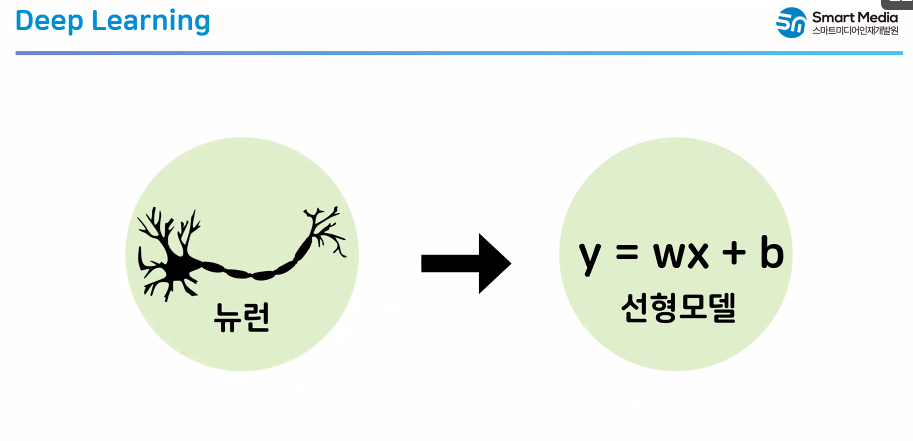
✅ Deep Learning 개념

✅ 기계 vs 사람




✅ 뉴런의 구조

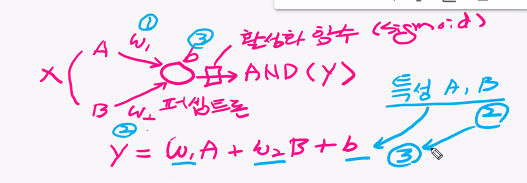
✅ 퍼셉트론

✅ 시냅스

✅ 퍼셉트론



✅ 다층 퍼셉트론





✅ 기존 머신러닝(선형모델)과 딥러닝의 공통점

✅ 기존 머신러닝(선형모델)과 딥러닝의 차이점

✅ 기존 머신러닝(선형모델)과 딥러닝의 선택


✅ Deep Learning의 성공요인


✅ 딥러닝 프레임워크




✅ 딥러닝 개발 환경 구축










✅ Google Drive 연동



✅ 구글 드라이브 마운트(연동)
from google.colab import drive
drive.mount('/content/drive')- 📌 작업 폴더로 이동
%cd /content/drive/MyDrive/Colab Notebooks/Deep Learning
!ls
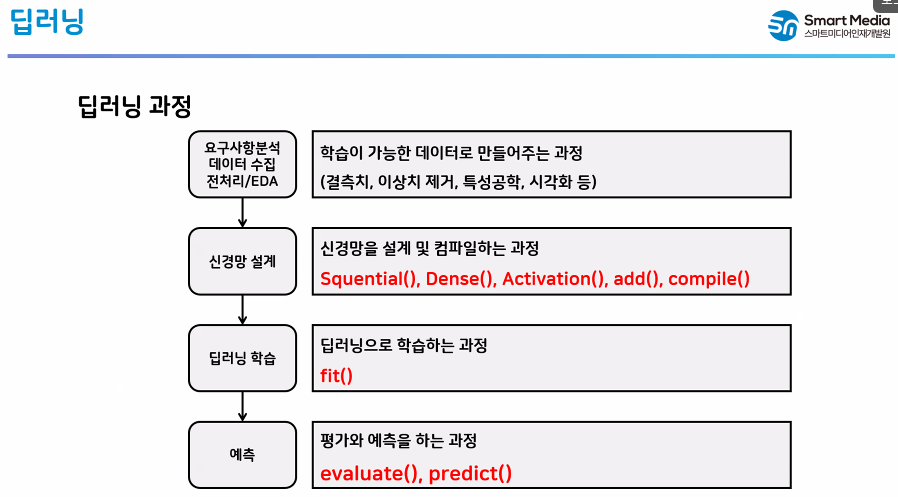
✅ 딥러닝 과정

✅ Keras로 신경망 설계
- Sequential() : 신경망을 초기화
- Dense() : 신경망 층을 정의
- add() : 정의된 신경망 층을 초기화한 신경망에 추가
- Activation() : 활성화 함수층 정의
- compile() : 설계된 신경망을 학습할 수 있는 형태로 변환
- fit() : 학습
- predict() : 추론
- evaluate() : 평가
✅ AND 논리 학습 모델을 설계하고 추론

- 📌 입력 데이터 정의
X = [[0, 0], [0, 1], [1, 0], [1, 1]]
y = [0, 0, 0, 1]- 📌 신경망 설계
import numpy as np
np.array(X).shape, np.array(y).shape
# 0번 인덱스 : 데이터의 수
# 1번 인덱스 : 특성의 수 -> input_dim -> 입력의 수
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
# 신경망 초기화
model1 = Sequential()
# add() : 신경망에 정의된 층을 추가
# Dense() : 신경망 층을 정의
# - units : 출력의 수 (퍼셉트론 수)
# - input_dim : 입력의 수 (특성 수) # 2개
model1.add(Dense(units=1, input_dim=2))
model1.add(Activation("sigmoid"))
# summary() : 설계된 신경망의 구조를 출력하는 함수
model1.summary()


- 📌 퍼셉트론 2개로 신경망 설계

model2 = Sequential()
# (1)
# 입력 데이터의 크기 (input_dim)은 첫번째 층에만 정의해주면 된다
model2.add(Dense(units=1, input_dim=2))
model2.add(Activation("sigmoid"))
# (2)
model2.add(Dense(units=1))
model2.add(Activation("sigmoid"))
model2.summary()
- 📌 퍼셉트론 5개로 구성된 신경망

model3 = Sequential()
# (1)
model3.add(Dense(units=4, input_dim=2))
model3.add(Activation("sigmoid"))
# (2)
model3.add(Dense(units=1))
model3.add(Activation("sigmoid"))
model3.summary() # w : 12, b : 5
- 📌 컴파일
- loss : 손실함수
- 회귀 분석 : mse 또는 mean_squard_error
- 이진 분류 : binary_crossentropy
- 다진 분류 : categorical_crossentropy
- optimizer : 최적화 함수 (adam)
- metrics : 평가 함수 (오차, 정확도)
- loss : 손실함수
model1.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
model2.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
model3.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])- 📌 학습
- epochs : 학습 반복수
- batch_size : 학습에 사용할 데이터 수
h1 = model1.fit(X, y, epochs=1000, batch_size=4)
- 📌 추론
pred = model1.predict([[1, 1]]) # 0.5 보다 크면 -> 1
pred
✅ XOR 논리 학습하기

X = [[0, 0], [0, 1], [1, 0], [1, 1]]
y = [0, 1, 1, 0]model1.fit(X, y, epochs=1000, batch_size=4)

model3.fit(X, y, epochs=1000, batch_size=4)

✅ 딥러닝 동작 방식 구현해보기
- (1) 파리미터 초기화 (w, b) - 랜덤
- (2) 특성 데이터(X)를 입력 -> 예측값 y'를 계산 (y' = wX + b)
- (3) 오차 계산 : e = y - y'
- 오차가 크다는 의미는 w, b가 잘못 설정이 된 것 - 오차가 발생한 만큼
- 예를 들어 w가 10이고 b가 1이면 w가 더 영향을 준 것
- w의 값은 줄이고 b값은 크게 재조정 -> 오차의 비율만큼
- (4) 오차에 대한 가중치를 미분 (나누기 - 비율)
- (5) 가중치 갱신 (미분값을 더해줌)
- 학습률 : 미분값이 커서 가중치가 너무 크게 변하는 것을 방지
- 특성 데이터를 넣고 위의 과정을 반복 (오차가 목표값보다 작아질 때까지)

import numpy as np
# X : 특성 데이터, y : 라벨 데이터, epoch : 반복수, lr : 학습률
def fit_user(X, y, epoch, lr) :
# (1) w, b 초기화
w = np.random.randn(1)
b = np.random.randn(1)
# (2) ~ (5)까지 epoch만큼 반복
for i in range(epoch) :
# (2) 특성 데이터를 입력하여 예측값을 계산
pred_y = w * X + b
# (3) 오차 계산 : 실제값 - 예측값
e = y - pred_y
# (4) 기울기(경사) 계산 - 미분 -> 경사하강법
dw = e / w
db = e / b
# (5) 원 가중치에 학습률을 곱한 기울기 값을 더해서 가중치를 갱신
w = w + lr * dw
b = b + lr * db
# 중간 결과값 출력
print(f'반복수 : {i}, 예측값 : {pred_y}, 오차 : {e}')
# 현재 파리미터 (w, b) 값 출력
# print(f'w : {w}, b : {b}')fit_user(1, 3, 100, 0.01)
✅ 딥러닝 회귀 분석
- 보스턴 집 값 데이터 셋
from tensorflow.keras.datasets import boston_housing
(X_train, y_train), (X_test, y_test) = boston_housing.load_data()
- 📌 랜덤값에 대한 seed 설정
- w, b를 랜덤으로 초기화 -> 신경망을 실행할 때마다 다른 w, b 초기값이 적용
- 모델 개선 시, 개선 이유가 모델에 의한 것인지 w, b의 초기값에 의한 것인지 구분이 안됨
- 팀원의 모델을 공유할 때 seed를 설정하지 않으면 공유한 모델을 그대로 적용할 수 없음
- w, b를 랜덤으로 초기화 -> 신경망을 실행할 때마다 다른 w, b 초기값이 적용
import numpy as np
import tensorflow as tf
np.random.seed(1)
tf.random.set_seed(1)X_train.shape, y_train.shape
- 📌 신경망 설계

from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
model4 = Sequential()
model4.add(Dense(units=30, input_dim=13)) # input_dim : 특성수
model4.add(Activation("relu"))
# 출력층 (마지막 층)
# units
# - 회귀모델 : 1
# - 이진분류 : 1 또는 2 (원핫 인코딩)
# - 다진분류 : 원핫 인코딩 후의 y 크기
# Activation()
# - 회귀모델 : linear 또는 생략
# - 이진모델 : sigmoid 또는 softmax (원핫 인코딩)
# - 다진모델 : softmax
model4.add(Dense(units=1))
model4.summary()
- 📌 컴파일
# loss : mse 또는 mean_squard_error
# metrics : 생략 -> loss로 인식
model4.compile(loss="mse", optimizer="adam")# validation_data : 검증 데이터를 설정 (테스트가 있는 경우)
# validation_split : 해당 비율 만큼을 검증 데이터로 사용 (검증 데이터가 없는 경우)
h4 = model4.fit(X_train, y_train, epochs=200, batch_size=10, validation_data=(X_test, y_test))
- 📌 시각화 하기
import matplotlib.pyplot as plt
plt.plot(h4.history["loss"], label="loss")
plt.plot(h4.history["val_loss"], label="val_loss")
plt.ylim(0, 200)
plt.legend()
plt.show()
- 📌 예측하기
pred = model4.predict(X_test)
for i in range(10) :
print(f'실제값 : {y_test[i]}, 예측값 : {pred[i][0] : .1f}') # : .1f -> 형식 지정
- 📌 모델 평가
model4.evaluate(X_test, y_test)
- 📌 이진분류 딥러닝 학습
- 유방암 데이터 셋
- 569개 데이터
- 악성, 양성 라벨
- 유방암 데이터 셋
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
cancer.keys()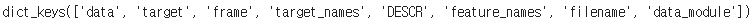
X = cancer.data
y = cancer.target
X.shape, y.shape
import pandas as pd
pd.Series(y).unique()
- 📌 이진 분류 신경망 모델 설계(라벨을 원핫 인코딩 하지 않는 경우)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
model5 = Sequential()
# 입력층
model5.add(Dense(units=32, input_dim=30))
model5.add(Activation("sigmoid"))
# 은닉층
model5.add(Dense(units=16))
model5.add(Activation("sigmoid"))
# 출력층
model5.add(Dense(units=1))
model5.add(Activation("sigmoid"))
model5.summary()

# 이진 분류 : "binary_crossentropy"
model5.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])# validation_split = 0.2 : 검증 데이터를 훈련 데이터에서 20% 가져다 쓴다
h5 = model5.fit(X, y, epochs=200, batch_size=16, validation_split=0.2)
import matplotlib.pyplot as plt
plt.plot(h5.history["accuracy"], label="accuracy")
plt.plot(h5.history["val_accuracy"], label="val_accuracy")
plt.legend()
plt.show()
plt.plot(h5.history["loss"], label="loss")
plt.plot(h5.history["val_loss"], label="val_loss")
plt.legend()
plt.show()
'Deep Learning' 카테고리의 다른 글
| 모델저장 학습중단 과적합 (0) | 2024.07.01 |
|---|---|
| mlp_활성화 함수, 최적화 함수 비교 패션 데이터 다중 분류 (0) | 2024.06.28 |
| iris 데이터 다중 분류 실습 (0) | 2024.06.27 |
| 폐암 데이터 이진 분류 (0) | 2024.06.26 |
| 학생 수학 성적 예측 (0) | 2024.06.26 |