학생 수학 성적 예측
2024. 6. 26. 08:55ㆍDeep Learning
✅ 딥러닝 개요









✅ 딥러닝 활용 사례


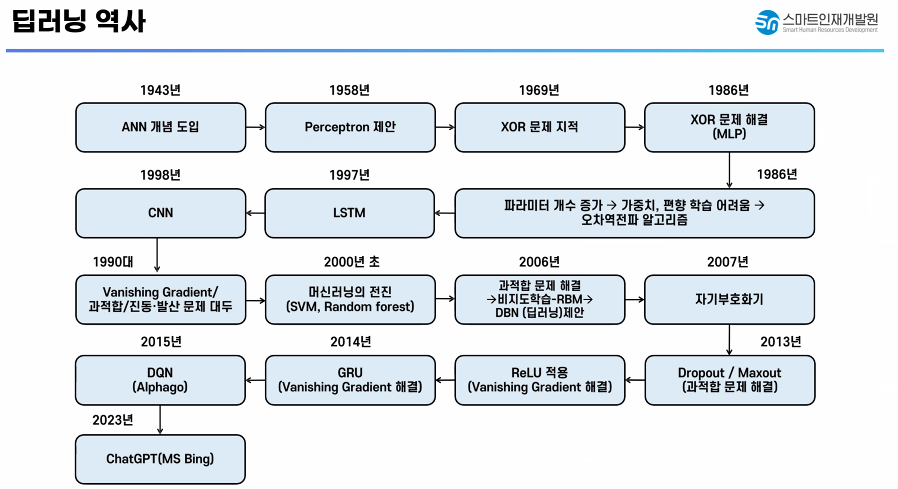
✅ 머신러닝(선형모델)과 딥러닝의 공통점

✅ 머신러닝과 딥러닝의 차이점


✅ 학습 로드맵
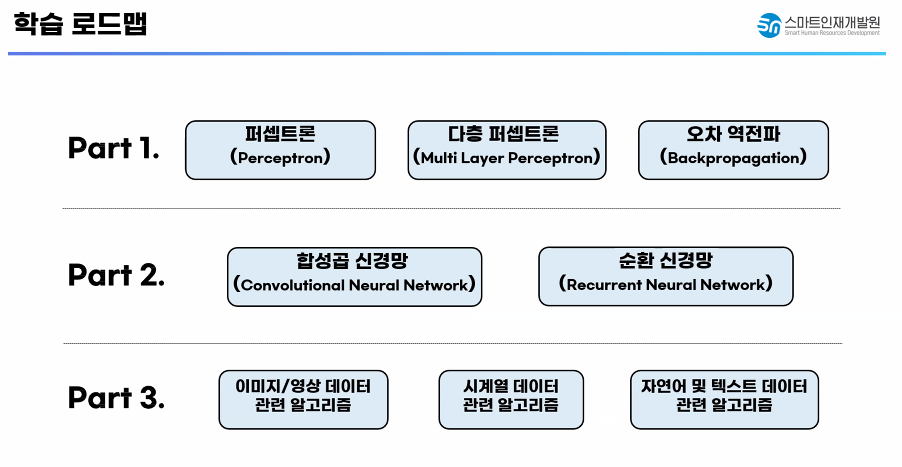
✅ 딥러닝 프레임워크

✅ 딥러닝에서 사용할 프레임워크
- Tensorflow(Tensorflow + Keras)
- 복잡한 신경망을 블록 형태로 쉽게 구현하도록 만든 딥러닝 프레임워크
# mount() : 장치를 특정한 위치에 연결해주는 함수
from google.colab import drive
drive.mount('/content/drive')

# 현재 우리 위치 확인해보기
!pwd
# 현재 파일이 있는 곳으로 기본경로 잡아주기
%cd /content/drive/MyDrive/Colab Notebooks/Deep Learning
!pwd
# 텐서플로우 설치 코드
# !pip install tensorflow# 텐서플로우 버전 체크
import tensorflow as tf
print(tf.__version__)
# 만약 ModuleNotFoundError가 발생한다면 설치가 안되어 있는거다!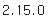
✅ 목표 설정
- 학생 성적 데이터를 이용해서 수학 성적을 예측하는 회귀 모델을 만들어 보자!
- tensorflow.keras를 이용해서 신경망을 구현하는 방법을 알아보자
# 기초 3종 라이브러리 import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 데이터 불러오기
data = pd.read_csv('data/student-mat.csv')
data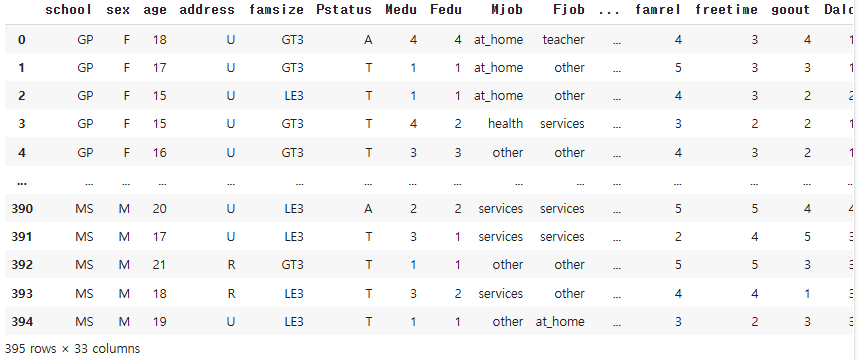
# 중간에 생략된 컬럼 전체 확인해보기
pd.set_option('display.max_columns', None)data
# 결측치 확인 - 결측치 없음 / object, int
data.info()
# 문제와 정답으로 분리
# 수학 점수 - G3
y = data.loc['G3']
# 문제 데이터 : school ~ absences까지 가져오기
X = data.loc[:, 'school':'absences']X.shape, y.shape
# 훈련 / 평가셋 분리
# train_test_split - 평가셋 30%, 랜덤 시드 = 20
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=20)X_train.shape, X_test.shape, y_train.shape, y_test.shape
✅ 신경망 모델 만들기
- 신경망 구조 설계
- 신경망 학습과 평가 방법 설정
- 학습 및 학습 과정 시각화
- 모델 평가 및 예측
# 신경망 구조 재료 가져오기(import)
# Sequential : 신경망 모델의 뼈대를 구현하는 함수
# 각자의 층을 선형으로 연결해주는 역할을 담당
from tensorflow.keras import Sequential
# Dense : 신경망의 층(뉴런의 묶음)을 설정하고 구성해주는 함수
# Activation : 활성화 시켜주는 함수
from tensorflow.keras.layers import Dense, Activation# 1. 딥러닝 모델은 뼈대에 층을 하나하나 차곡차곡 쌓아주는 형태로 구현
# 입력층 -> 중간층 -> 출력층의 순서로 구현
model = Sequential()
# 입력층 설정
model.add(Dense(units = 4, input_dim = 1))
# add : 층을 추가하는 함수 / units = 뉴런의 갯수 설정 / input_dim = 입력할 데이터가 가진 특성의 갯수(사용할 특성의 갯수모델은 뼈대에 층을 하나하나 차곡차곡 쌓아주는 형태로 구현)
model.add(Activation('sigmoid'))
# 출력층 설정
model.add(Dense(units = 1))
# 모델 요약
model.summary()
# 2. 신경망 학습 / 평가 방법 설정
# compile() : 앞서 만든 모델이 효과적으로 구현될 수 있도록 환경 설정을 하면서 읽어오는 함수
# 모델을 학습시키기 전 손실함수, 최적화 방법, 평가지표를 설정하는 부분
model.compile(loss = 'mse', optimizer = 'SGD')
# 손실함수 : 현재는 회귀 분석 진행 중, 평균 제곱 오차를 이용해서 에러 체크 -> mse
# 최적화 함수 : 모델의 성능을 최적화 시키는 방법 설정 -> 확률적 경사하강법 -> SGD
# 모델의 성능 평가지표 설정 부분 -> metrics = 'mse'# 3. 모델 학습
# epochs = 학습을 얼마나 시킬 것인가?
h = model.fit(X_train['studytime'], y_train, epochs = 100)
h.history['loss']
plt.plot(h.history['loss'])
# 학습된 모델을 이용해서 예측을 진행해보자
model.predict(X_test['studytime'])
# 모델 성능 측정
model.evaluate(X_test['studytime'], y_test)
✅ 퍼셉트론
- 신경망을 구성하는 가장 작은 단위
- 선형 회귀식 + 활서오하 함수를 추가한 것
- -> 인간 신경망의 역치(문턱값)를 구하기 위해 활성화 함수를 추가했다.






✅ Sequential
- 신경망의 기초 뼈대 구축 / 선형으로 연결해주는 기능
✅ Dense
- 층을 정의하는 함수(유닛(뉴런의 갯수) 등등)
✅ model.add() - 층을 추가해주세요!
- ()안에 Dense라는 함수 들어감!
✅ model.compile(loss(손실함수) = , optimizer(최적화함수) = , metrics(평가지표) = )
✅ fit - 훈련
✅ predict - 예측
✅ evaluate - 평가(성능 확인)
✅ 퍼셉트론 - 인공 신경망을 구성하는 가장 기본 단위
- 1958년 도입
✅ 초기 활성화 함수

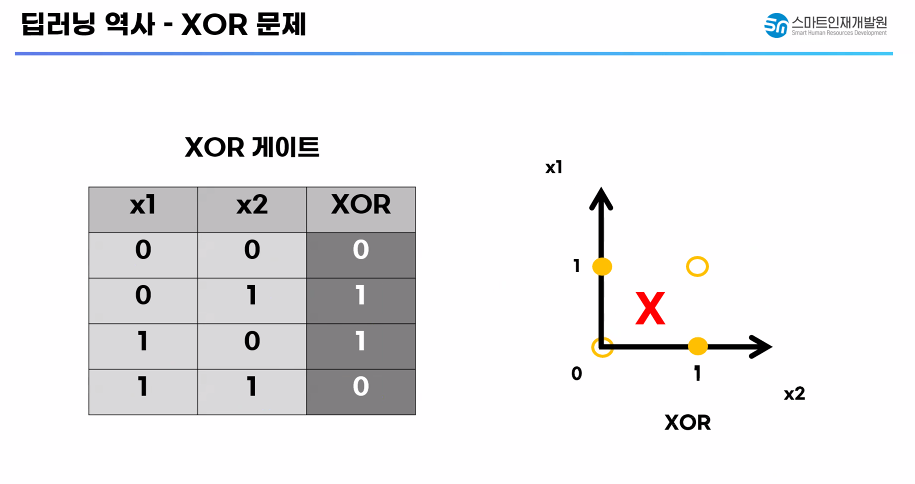
✅ 딥러닝 역사 - XOR 문제


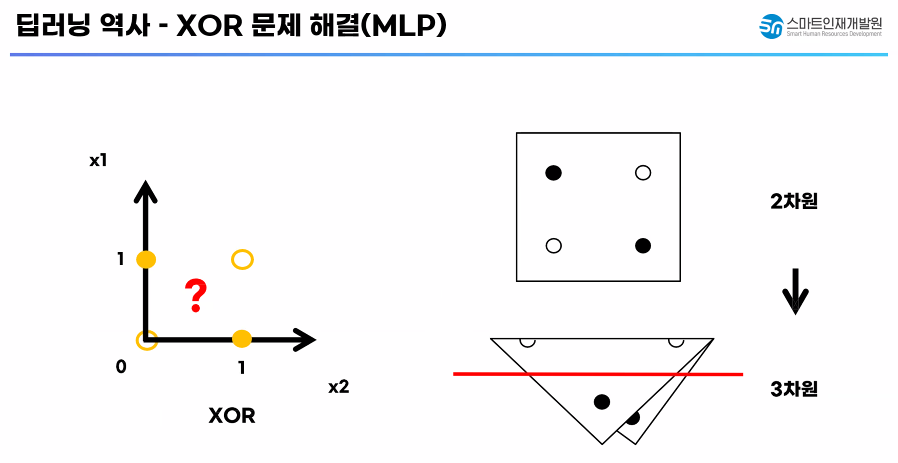
✅ 딥러닝 역사 - XOR 문제 해결(MLP)






✅ 다층 퍼셉트론


# 2개의 특성을 넣어서 작동하는 모델을 만들어보자
data.columns
# X1이라는 변수에 2가지 특성을 담아주자.(traveltime, studytime)
X1 = data[['traveltime', 'studytime']]
y1 = data['G3']X1.shape
# 훈련 데이터 셋과 평가 데이터 셋 분할
X1_train, X1_test, y1_train, y1_test = train_test_split(X1, y1, test_size=0.3, random_state=20)X1_train.shape, X1_test.shape, y1_train.shape, y1_test.shape
# 신경망 구조 설계
model1 = Sequential() # 인공 신경망의 뼈대를 생성
# 입력층 설정
model1.add(Dense(units = 4, input_dim = 2)) # shape 특성의 개수가 2개였기 때문에 input_dim = 2
model1.add(Activation('sigmoid'))
# 중간층 설정
model1.add(Dense(units = 2))
model1.add(Activation('sigmoid'))
# 출력층 설정
# 출력값 1개 설정하기 위해 뉴런을 1개만 주세요
# 활성화 함수는 생략하겠습니다.
model1.add(Dense(units = 1))
# 신경망 요약
model1.summary()
# 모델 컴파일
model1.compile(loss = 'mse', optimizer = 'SGD') # 확률적 경사 하강법(SGD)from ssl import HAS_TLSv1_1
# 모델 학습
h1 = model1.fit(X1_train, y1_train, epochs = 100)
model1.evaluate(X1_test, y1_test)
# 3. 입력 특성을 전부 넣어보자
X_train.info()
X_test.info()
# 원핫 인코딩 진행합시다
X_train_oh = pd.get_dummies(X_train).astype(int)
X_test_oh = pd.get_dummies(X_test).astype(int)X_train_oh.shape, X_test_oh.shape
# 모든 입력 특성을 이용해서 신경망을 학습 / 평가해보자
# 문제 데이터 X_train, X_test
# 정답 데이터 y_train, y_test
# 신경망 구축
# 뼈대 설정
model2 = Sequential()
# 입력층
# 뉴런의 갯수 4개 / input_dim = 입력 특성 갯수 맞추기
# 활성화 함수는 sigmoid
model2.add(Dense(units = 4, input_dim = 56))
model2.add(Activation('sigmoid'))
# 중간층
# 뉴런의 갯수 2개
# 활성화 함수는 sigmoid
model2.add(Dense(units = 2))
model2.add(Activation('sigmoid'))
# 출력층
# 뉴런의 갯수 1개
# 활성화 함수 생략
model2.add(Dense(units = 1))
# 모델 요약
model2.summary()
# 2. 학습 / 평가 방법 설정
model2.compile(loss = 'mse', optimizer = 'SGD')# 3. 모델 학습
h2 = model2.fit(X_train_oh, y_train, epochs = 100)
plt.plot(h.history['loss'], label = 'h') # 단층 퍼셉트론
plt.plot(h1.history['loss'], label = 'h1') # 특성 2개 적용
plt.plot(h2.history['loss'], label = 'h2') # 특성 56개 적용
plt.legend()
plt.show()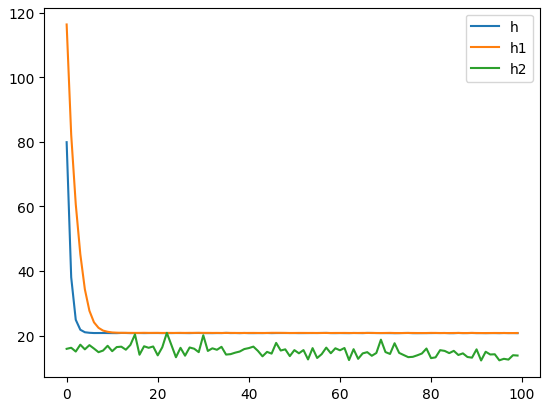
'Deep Learning' 카테고리의 다른 글
| 모델저장 학습중단 과적합 (0) | 2024.07.01 |
|---|---|
| mlp_활성화 함수, 최적화 함수 비교 패션 데이터 다중 분류 (0) | 2024.06.28 |
| iris 데이터 다중 분류 실습 (0) | 2024.06.27 |
| 폐암 데이터 이진 분류 (0) | 2024.06.26 |
| 딥러닝 기초 (0) | 2024.06.20 |