Logistic Regression
2024. 6. 14. 17:44ㆍMachine Learning
✅ 학습 목표

✅ 로지스틱 회귀란?
✅ 선형 모델 방식을 분류에 사용하는 이유
✅ 선형 모델 - Logistic Regression
📌 Sigmoid 함수 중요!
- 0과 1을 넘어가지 않음 -> 이진 분류를 명확하게 잡아줄 수 있음!
✅ 주요 매개변수
✅ 목표
- 손글씨 데이터 숫자(0~9)를 분류하는 모델을 만들어 보자
- 분류 모델의 불확실성을 확인하고 이해
- 이미지 데이터의 형태를 알아보자
# 필요한 라이브러리 import
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
# 데이터 가져오기
digit = pd.read_csv('data/digit_train.csv')
digit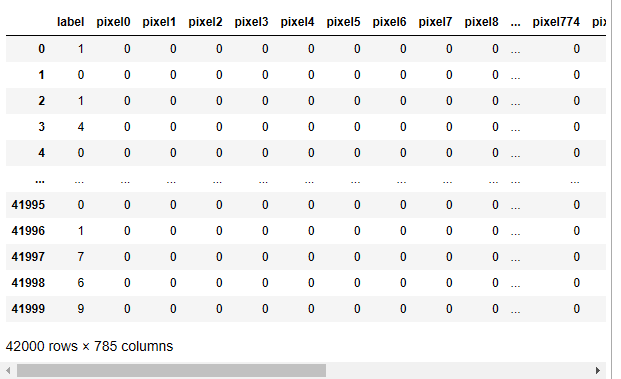
- 📌 데이터 분석
- label : 0~9까지 정답이 들어있는 컬럼
- pixelXXX : 이미지의 픽셀 정보 값이 들어있는 컬럼
✅ 전처리
- 학습용 데이터이기에 깔끔하게 처리되어 있다.
✅ EDA
img0 = digit.iloc[0, 1 : ]print(img0.min())
print(img0.max())
# 현재 손글씨 데이터는 흑백 데이터
# 0인 경우 검은색
# 1인 경우 흰색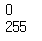
plt.hist(img0, bins=255)
plt.show()
# 이미지 출력 방법
img0 = digit.iloc[32000, 1 : ]
plt.imshow(img0.values.reshape(28, 28), cmap='gray')
plt.show()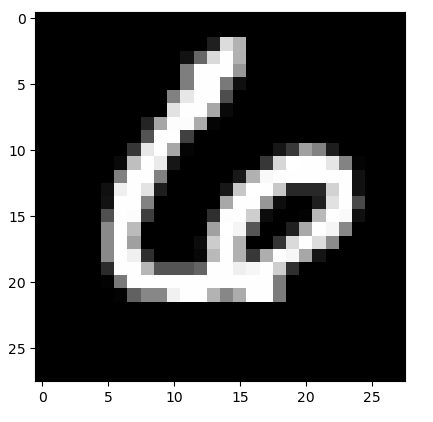
rs = digit.iloc[32000, 0]
rs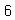
# 이미지 출력 방법
img0 = digit.iloc[1273, 1 : ]
plt.imshow(img0.values.reshape(28, 28), cmap='gray')
plt.show()
rs = digit.iloc[1273, 0]
print(rs)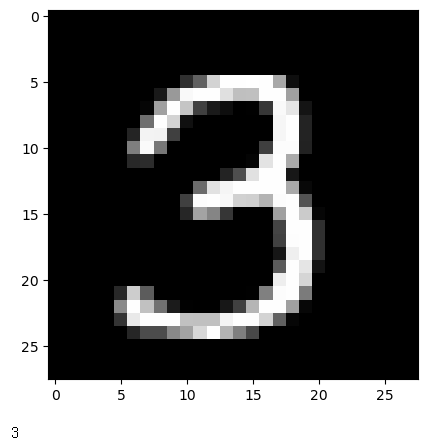
# 문제 / 정답 나눠주기
X = digit.iloc[ : , 1 : ]
y = digit['label']
✅ 선형 분류모델 사용하기
# model import
from sklearn.linear_model import LogisticRegression# 모델 객체 생성
logi = LogisticRegression()# 데이터 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.3,
random_state=7)# 모델 학습
logi.fit(X_train, y_train)
# 모델 성능 평가
logi.score(X_test, y_test)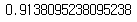
# 모델 예측
pre = logi.predict(X_test)
pre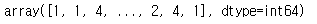
✅ 스케일링 적용
from sklearn.preprocessing import MinMaxScalermm_scale = MinMaxScaler()mm_scale.fit(X_train)
# 스케일링 적용
X_train_mm = mm_scale.transform(X_train)
X_test_mm = mm_scale.transform(X_test)plt.hist(X_train_mm[0])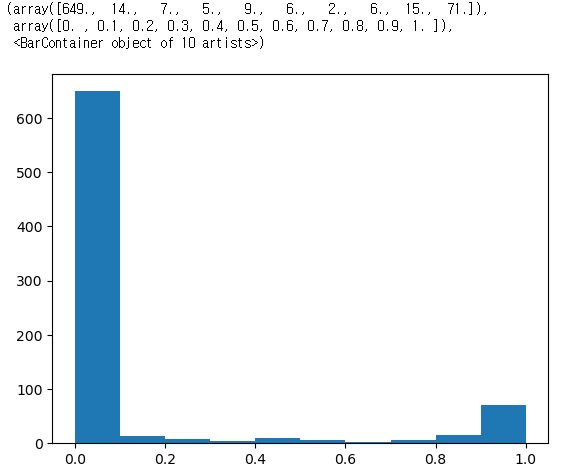
logi2 = LogisticRegression()
logi2.fit(X_train_mm, y_train)
logi2.score(X_test_mm, y_test)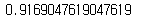
# knn 모델 사용해보기
from sklearn.neighbors import KNeighborsClassifierknn.fit(X_train_mm, y_train)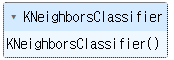
knn.score(X_test_mm, y_test)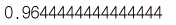
✅ 분류 예측의 불확실성
# predict_proba : 분류 예측을 진행할 때 각 정답별 예측 확률을 보여주는 기능
knn.predict_proba(X_test.values[50:80])
- 📌 predict_proba : 각 정답별 예측 확률을 뽑아서 가장 높은 확률을 가진 정답을 예측값으로 도출
- 각 확률 중 가장 높은 확률 값만 가져와서 현재 집어넣은 데이터에 예측 퍼센테이지를 추출해서 출력해서 사용할 수 있다.
'Machine Learning' 카테고리의 다른 글
| 규제 (1) | 2024.06.14 |
|---|---|
| 보스턴 주택 데이터 회귀분석 (0) | 2024.06.14 |