규제
2024. 6. 14. 16:02ㆍMachine Learning
✅ 규제

✅ 학습 목표

✅ 선형 회귀 수업 흐름도

✅ 규제란?

✅ 선형 회귀

✅ 모델 정규화
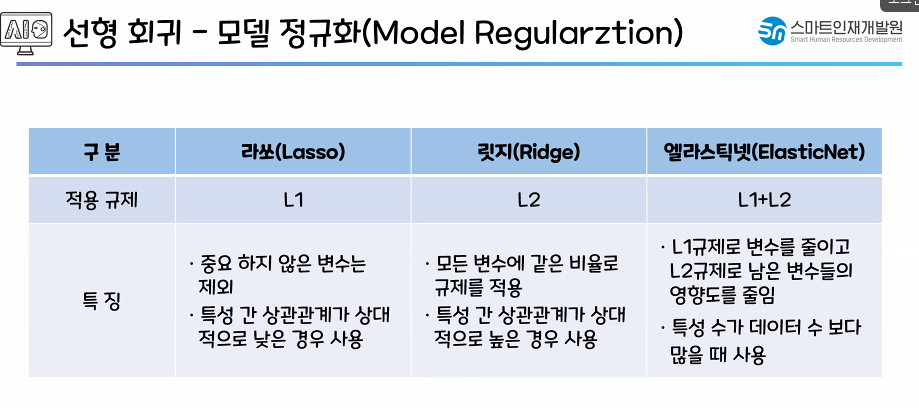
- L2 규제를 더 자주 씀!


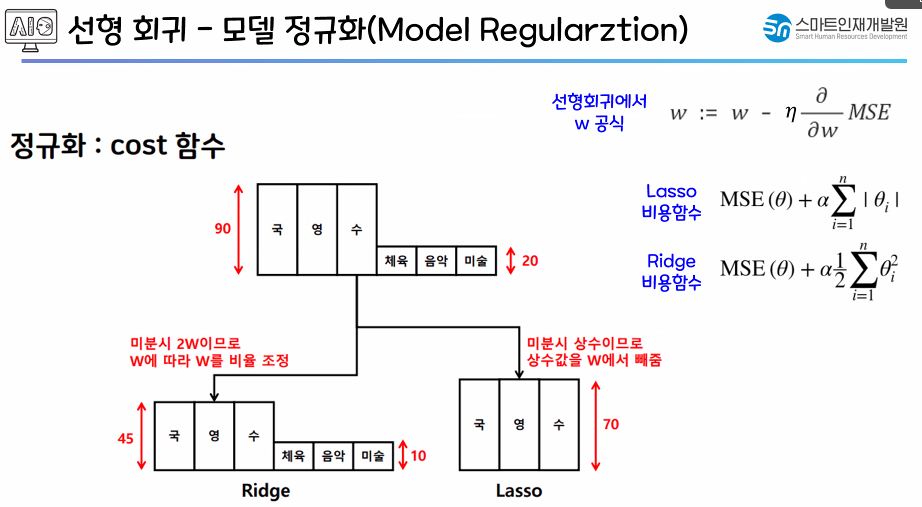
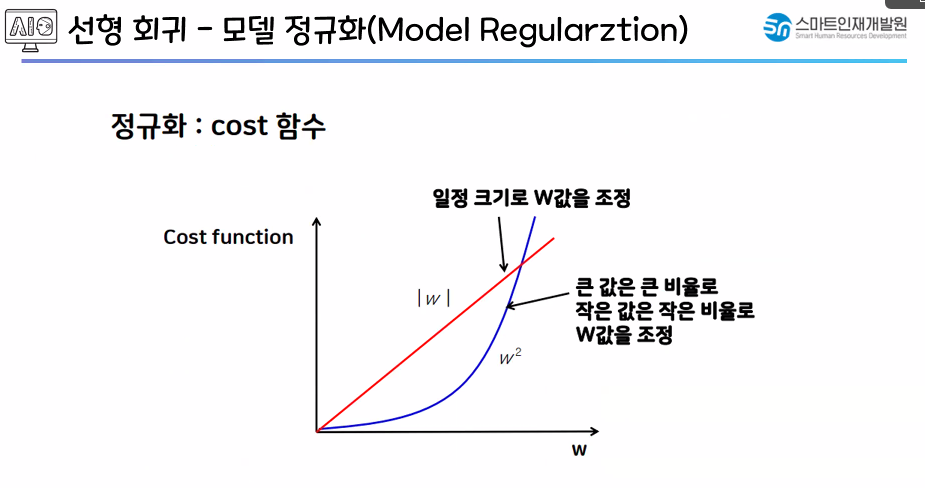
- 가중치 크기로 중요도를 판단!

✅ L2 - Ridge
# 모델 import
from sklearn.linear_model import Ridgeridge_model = Ridge(alpha=100)ridge_model.fit(extend_X_train, y_train)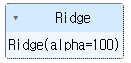
ridge_model.score(extend_X_test, y_test)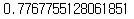
ridge_model.score(extend_X_train, y_train)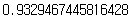
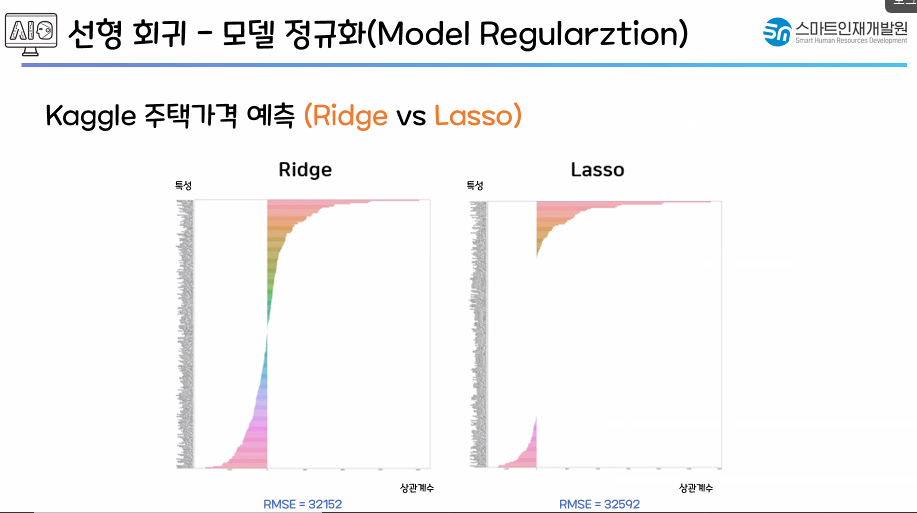
- 📌 test 성능은 좋아졌는데 과대적합은 완전하게 해소하지 못했다.
✅ L1 - Lasso
from sklearn.linear_model import Lassolasso_model = Lasso(alpha=100)lasso_model.fit(extend_X_train, y_train)
lasso_model.score(extend_X_test, y_test) # 일반보다 상승, 릿지보다 하락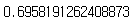
lasso_model.score(extend_X_train, y_train)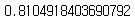
- 📌 현재 데이터는 라쏘가 조금 더 유리한 것 같다
- 특성 확장으로 인해 무의미한 특성들이 많이 늘어있는 상태
- 조건이 복잡해서 과대적합 발생!
- 무의미한 특성을 제외(가중치가 0이 되는)하는 Lasso모델이 조금 더 유리해 보인다.
✅ 규제별 규제강도에 따른 가중치의 변화값 확인해보기
alpha_list = [0.001, 0.01, 0.1, 10, 100, 1000] # 규제 강도 모음집 / 기본값 1 -> 제외
ridge_coef_list = [] # 릿지모델 가중치 리스트
lasso_coef_list = [] # 라쏘모델 가중치 리스트
# 릿지모델과 라쏘모델 가중치 변경하면서 학습 시켜보기(반복문 사용)
for alpha in alpha_list :
# 모델 설정 부
r_model = Ridge(alpha=alpha)
l_model = Lasso(alpha=alpha)
# 모델 학습 부
r_model.fit(X_train, y_train)
l_model.fit(X_train, y_train)
# 빈 리스트에 가중치 넣어주기
ridge_coef_list.append(r_model.coef_)
lasso_coef_list.append(l_model.coef_)# 라쏘 정규화 규제 강도별 가중치 확인해보기
lasso_df = pd.DataFrame(np.array(lasso_coef_list).T,
columns=alpha_list,
index=X_train.columns)
lasso_df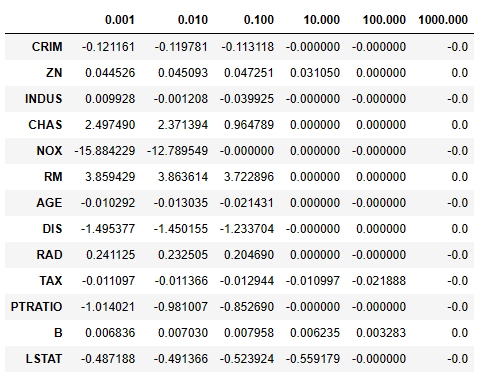
ridge_df = pd.DataFrame(np.array(ridge_coef_list).T,
columns=alpha_list,
index=X_train.columns)
ridge_df'Machine Learning' 카테고리의 다른 글
| Logistic Regression (0) | 2024.06.14 |
|---|---|
| 보스턴 주택 데이터 회귀분석 (0) | 2024.06.14 |