Yolo7 기반 객체 탐지 및 인식
2024. 7. 10. 14:06ㆍDeep Learning
✅ 학습 목표
- 이미지 데이터 라벨링 (roboflow)
- YOLO7으로 라벨링된 데이터 학습
- 객체 탐지 및 인식
- 📌 객체 탐지 (Object Detection)
- 컴퓨터 비전과 이미지 처리 기술을 이용해서 객체의 위치를 탐지하는 기술
- 객체 탐지를 위해서는 라벨 (annotation) 된 데이터 셋을 학습해야 함
- 📌 객체 인식 (Object Recognition)
- 탐지된 객체가 무엇인지 측정하는 기술
- 학습된 모델을 활용
- 📌 객체 탐지 기술
- two-stage detector : 객체 탐지와 인식(분류)를 순차적으로 따로 수행하는 방법
- 정확도는 높지만 속도가 느림
- R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN
- one-stage detector : 객체 탐지와 인식(분류)를 동시에 수행하는 방법
- two-stage detector에 비해 정확도는 낮지만 속도가 빠름
- Yolo (You Only Look Once : 한번만 보고 처리한다)
- YoloV9까지 출시 최근 YoloV10도 출시
- two-stage detector : 객체 탐지와 인식(분류)를 순차적으로 따로 수행하는 방법
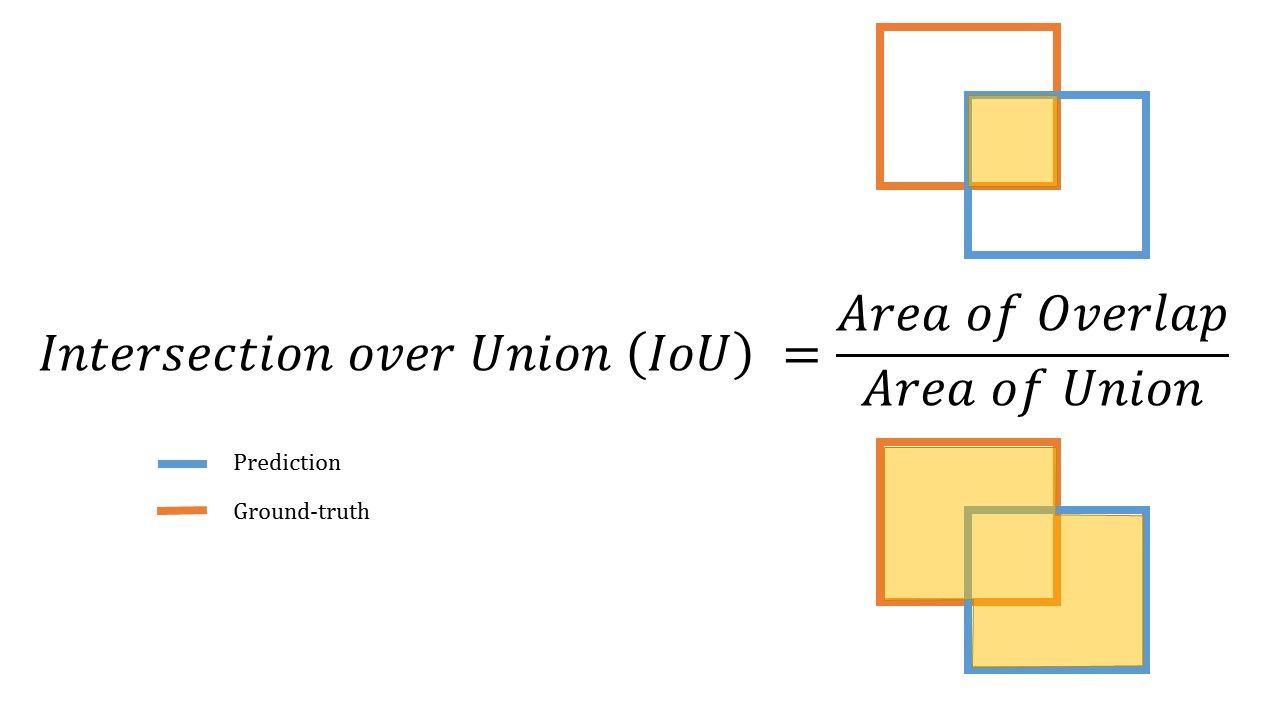
- 📌 탐지된 객체 위치 표시 방법 (Bounding Box)
- 객체의 위치를 사각형 영역으로 표시하는 방법
- 사각형 영역을 표시하는 방법
- 좌상단 좌표, 우하단 좌표 (lx, ly, rx, ry)
- 좌상단 좌표, 너비, 높이 (lx, ly, w, h)
- 좌상단 좌표, 중앙점 좌표 (lx, ly, cx, cy) -> Yolo
- 일반적으로 절대 좌표 보다는 비율을 사용해서 정규화 해서 활용

- 📌 annotation 방법 : 라벨링 방법
- bounding box : 객체의 영역을 사각형으로 표시하는 방법
- 쉽고 빠르게 작업이 가능
- 객체가 아닌 부분이 포함됨
- bounding box : 객체의 영역을 사각형으로 표시하는 방법

- 📌 polygon : 객체의 경계면을 따라서 점으로 표시하는 방법
- 작업 속도가 약간 느림
- 실제 객체의 영역만을 표시할 수 있음
- 객체가 겹쳐 있는 경우 정확한 인식이 어려움

- 📌 polyline : 객체의 경계면을 따라서 선으로 표시하는 방법
- 경계면이 복잡하거나 큰 객체에는 polygon을 사용

- 📌 point : 객체의 중심점으로 표시하는 방법
-
- 객체의 위치로만 표시

-
- 📌 cuboid : 육면체 형태 3D로 객체의 위치를 표시하는 방법
- 주로 로봇에 사용
- 시간이 많이 걸림

- 📌 Semantic segmentation : 객체의 영역들을 색상으로 채색하여 표시하는 방법
- 가장 정확도가 높은 방법
- 작업 시간이 많이 걸림

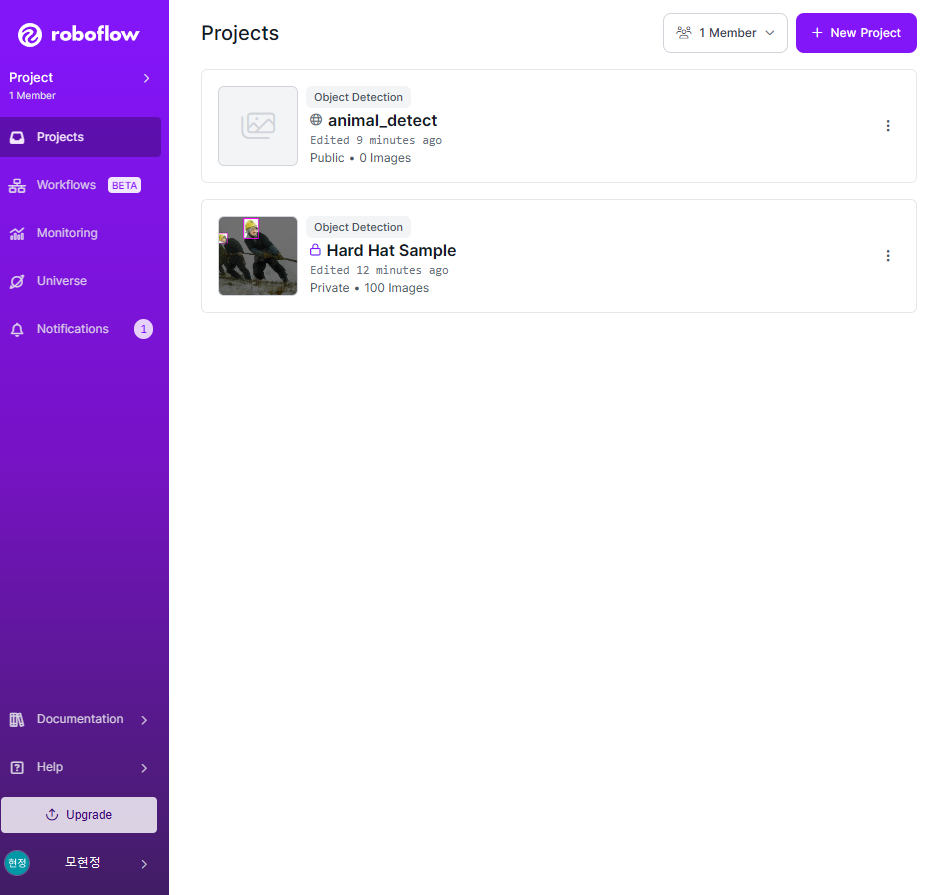
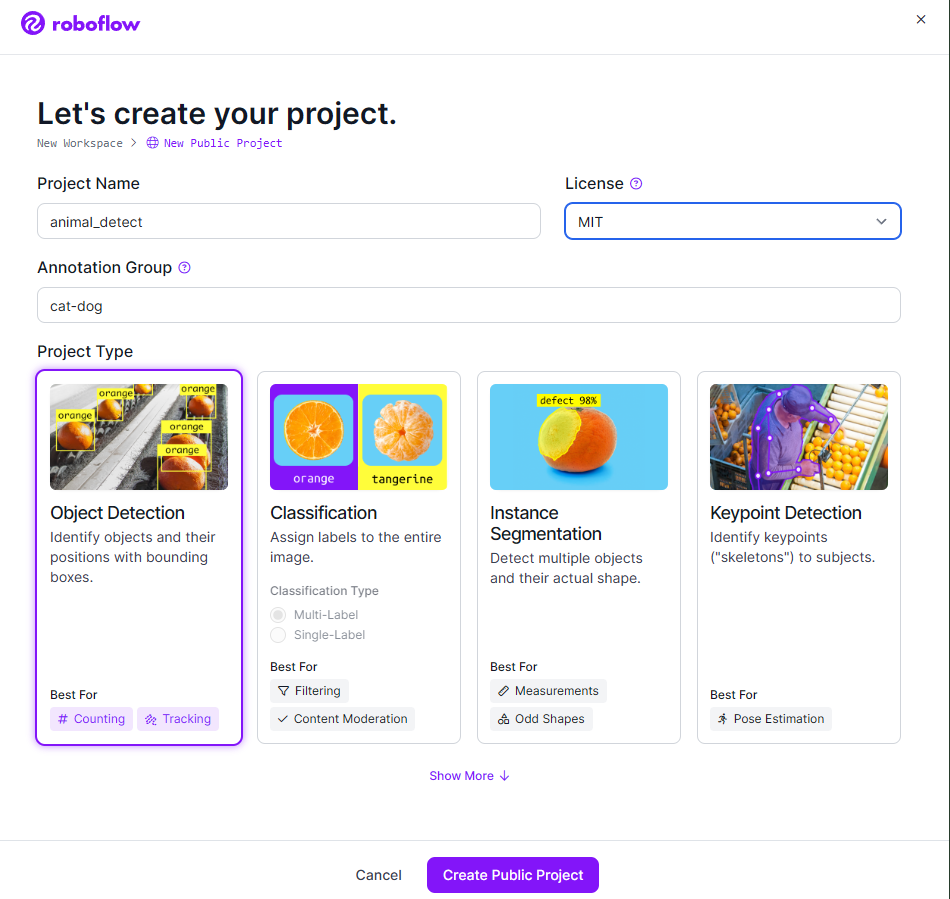
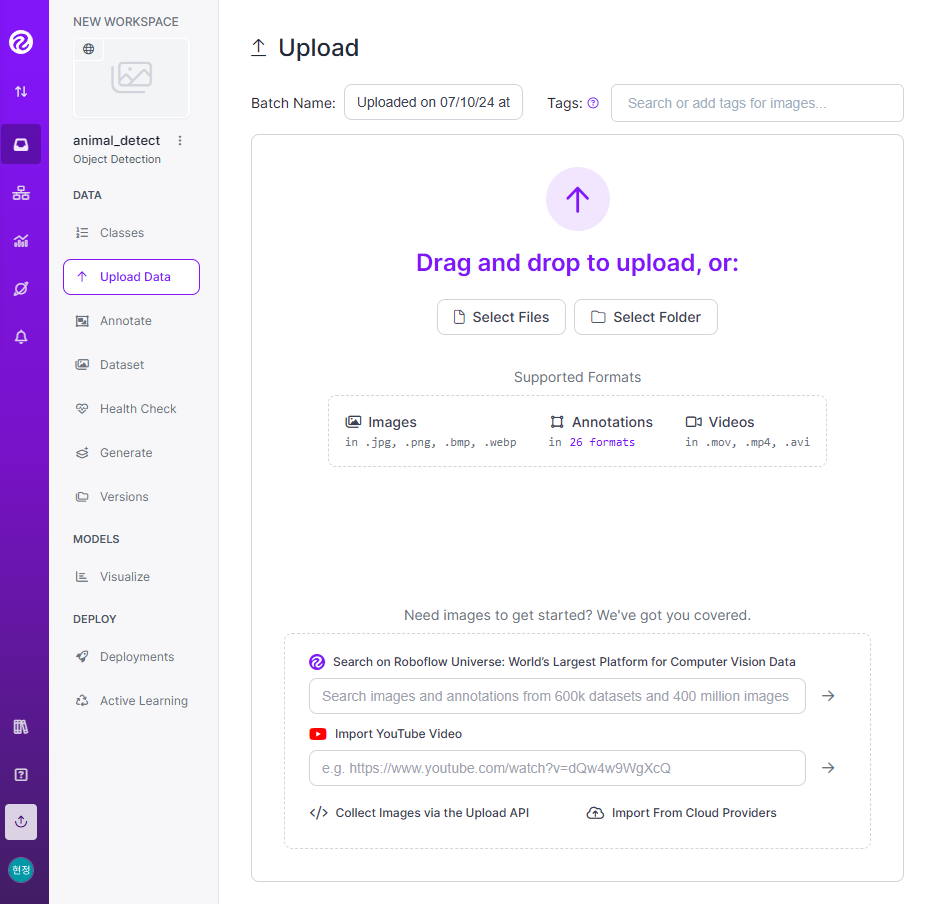
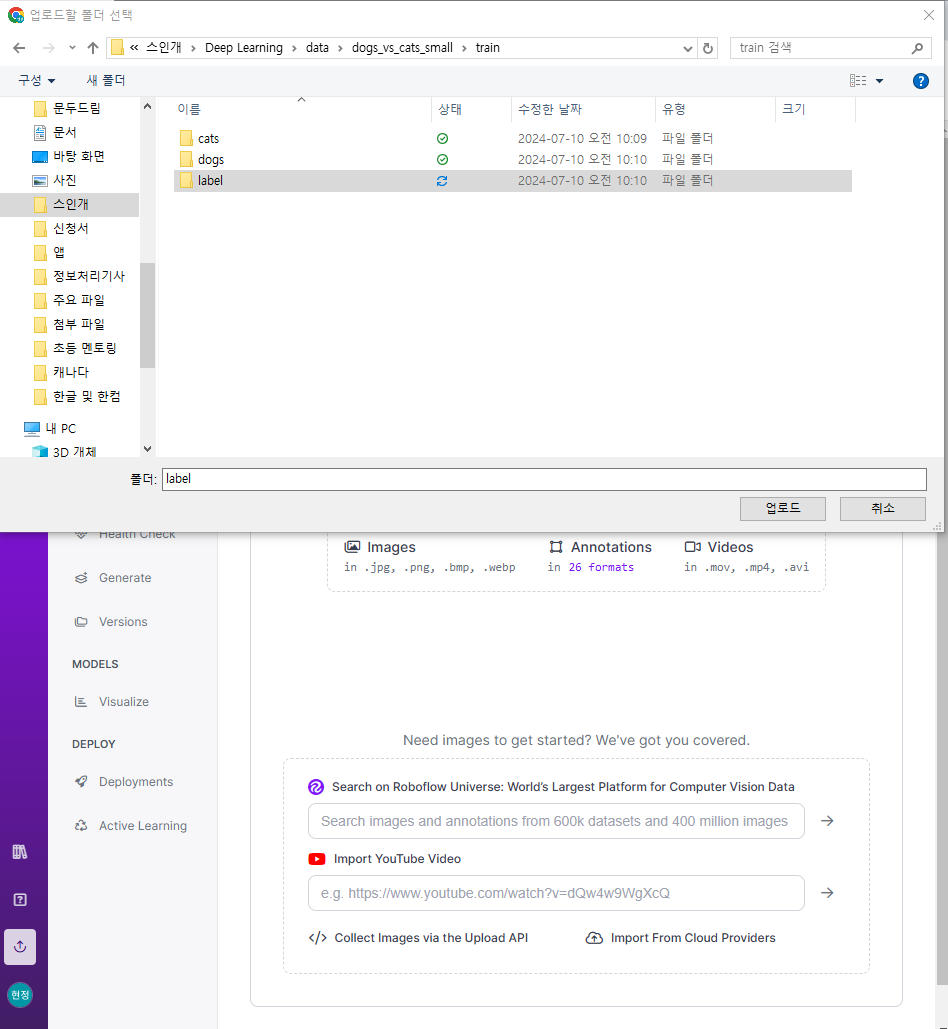
✅ roboflow를 이용한 라벨링
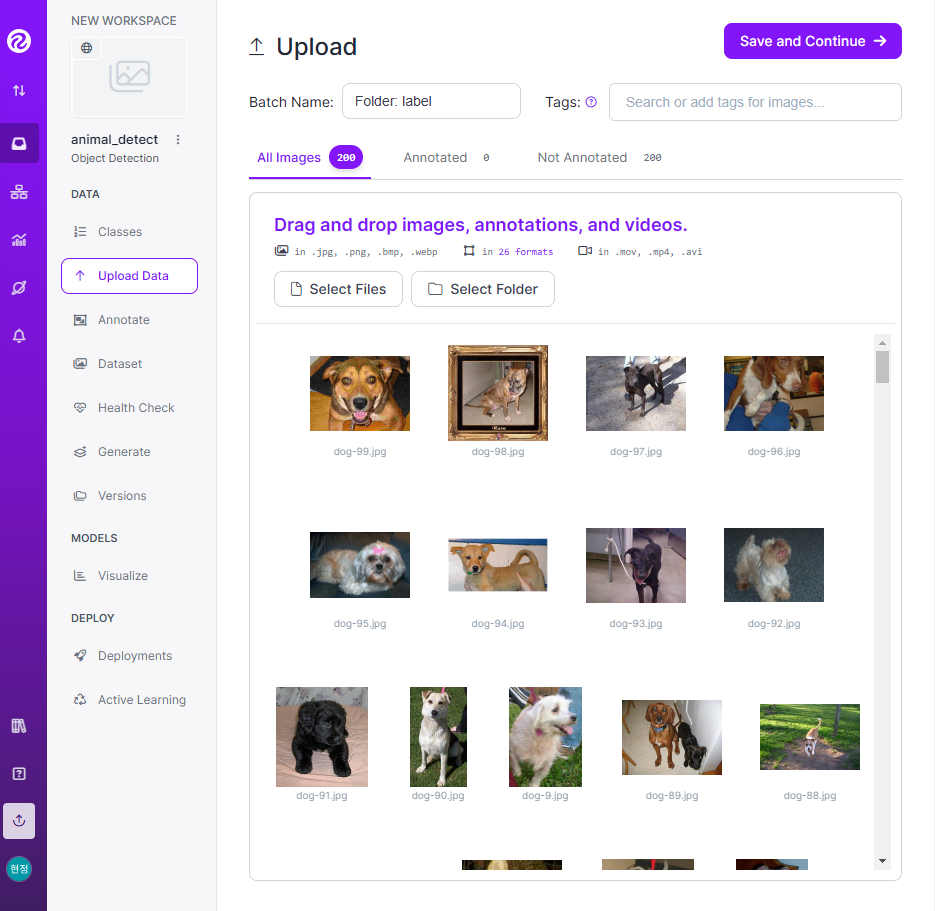
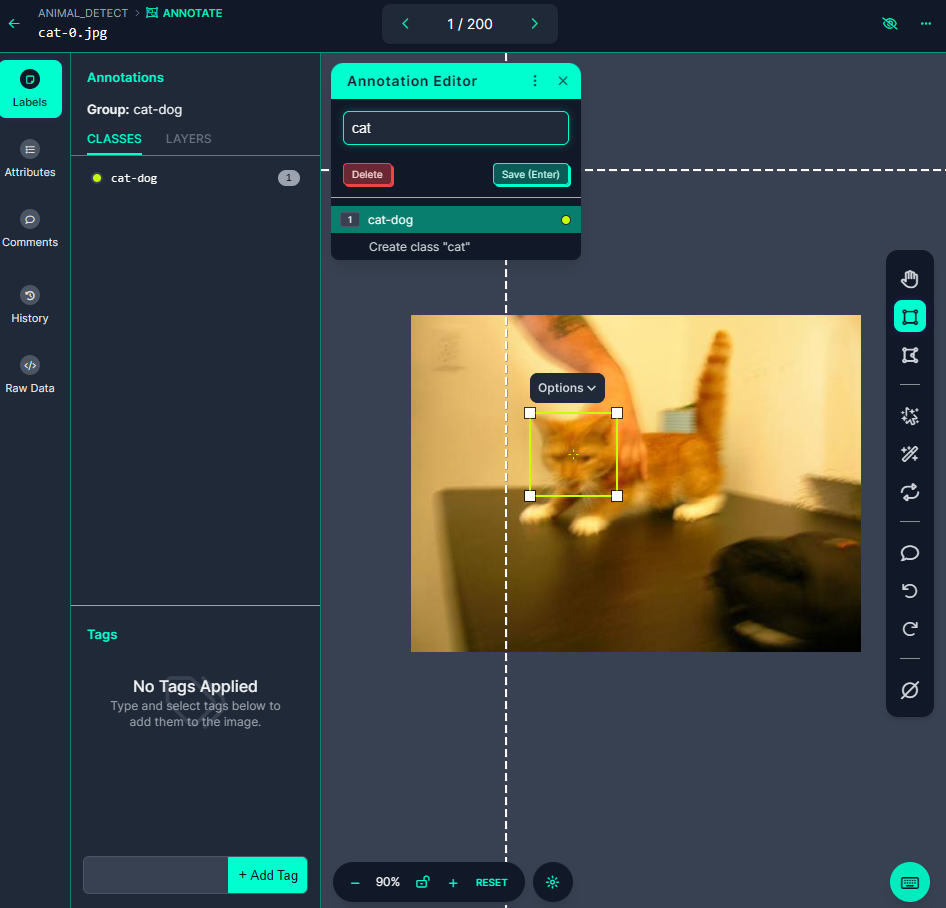
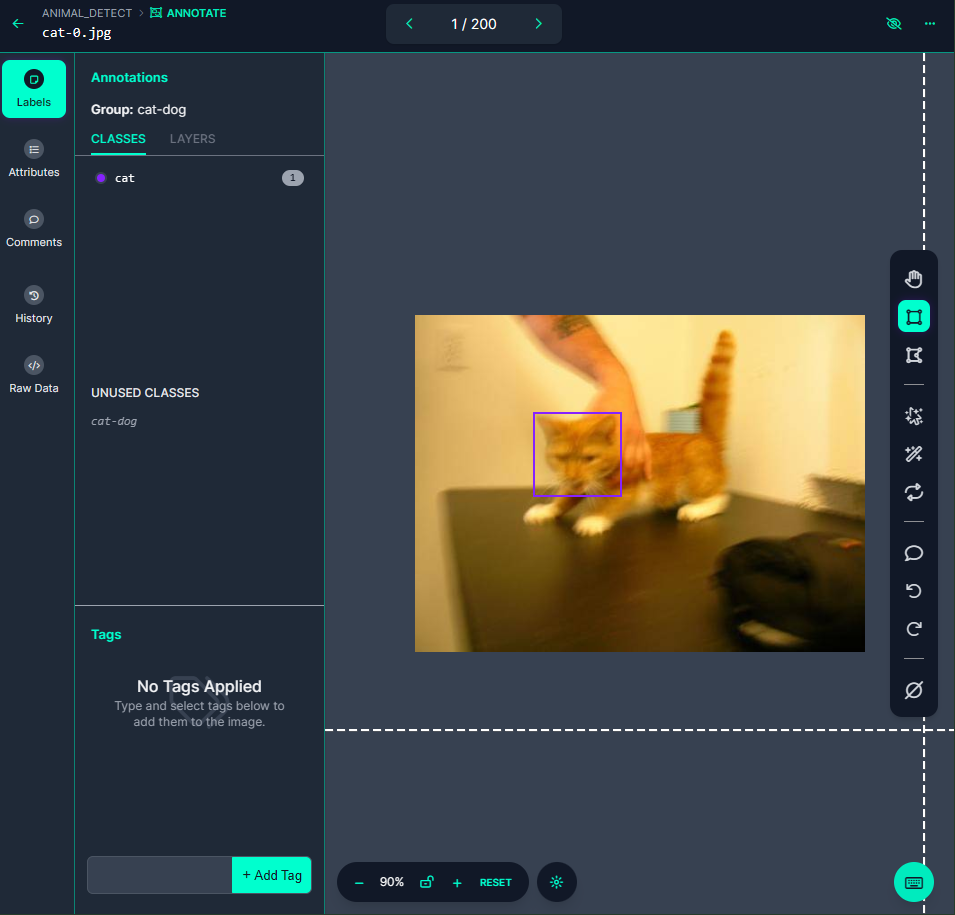
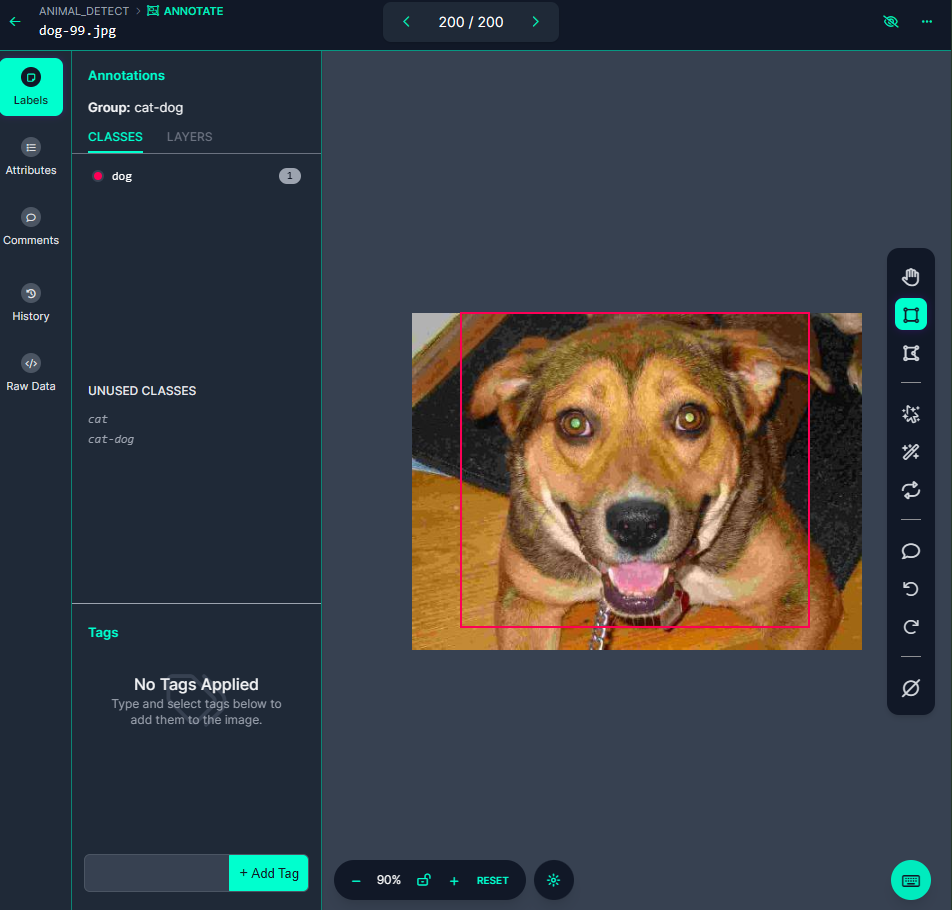
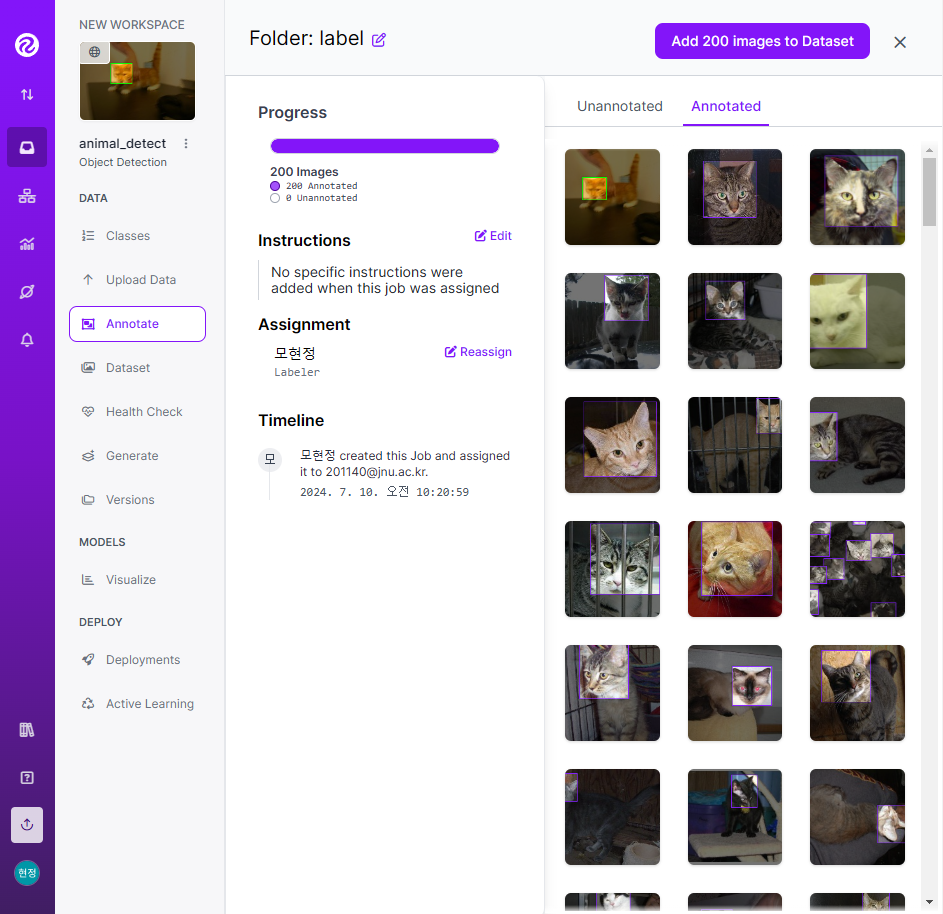
- 개/고양이 이미지 100개씩 총 200개를 라벨링
- https://roboflow.com/ 에 접속하고 로그인
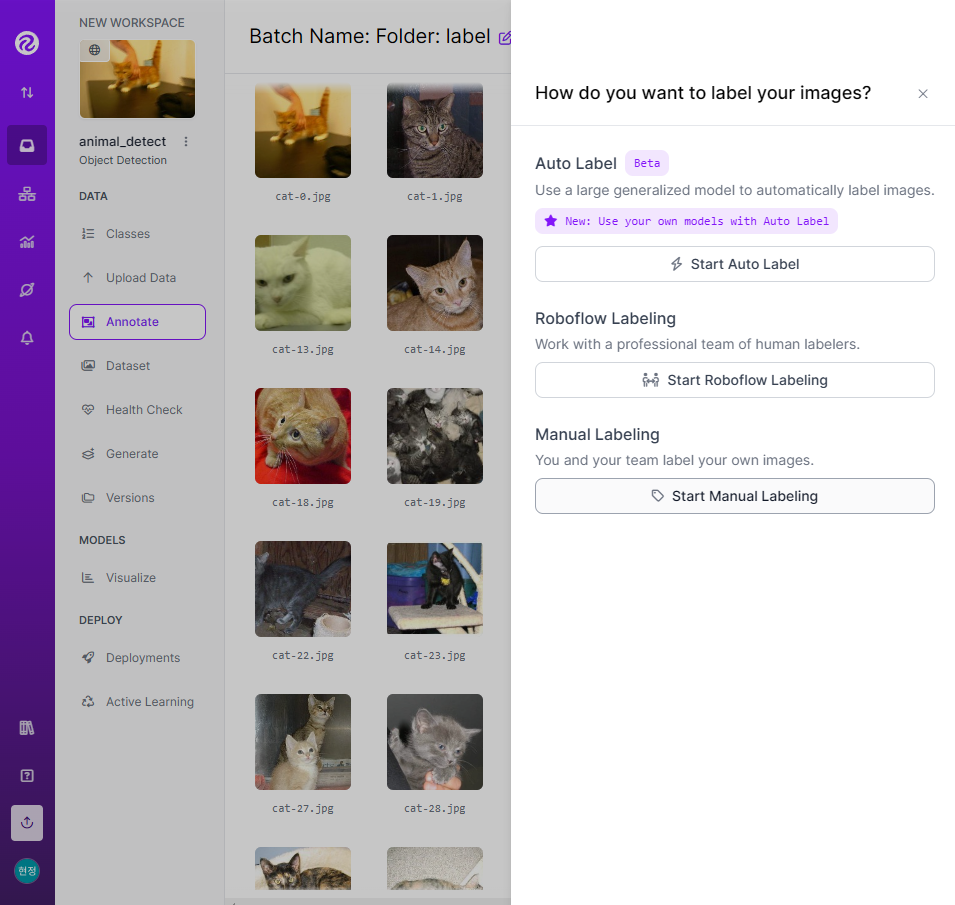
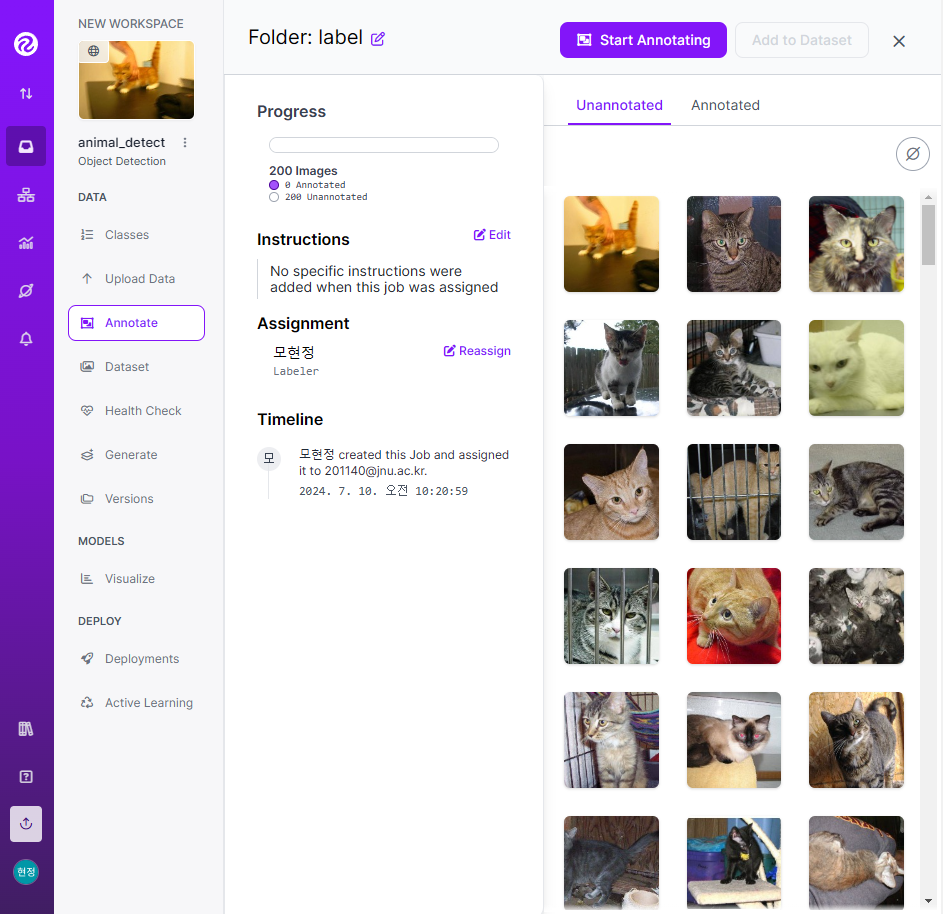
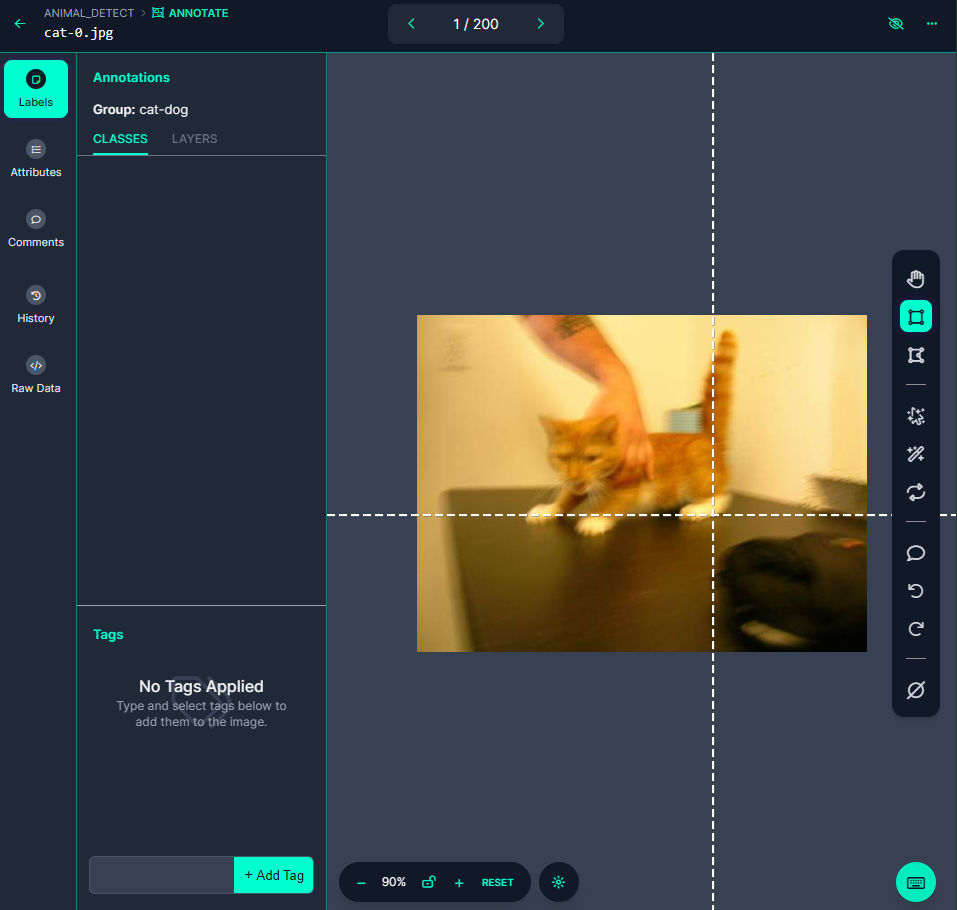
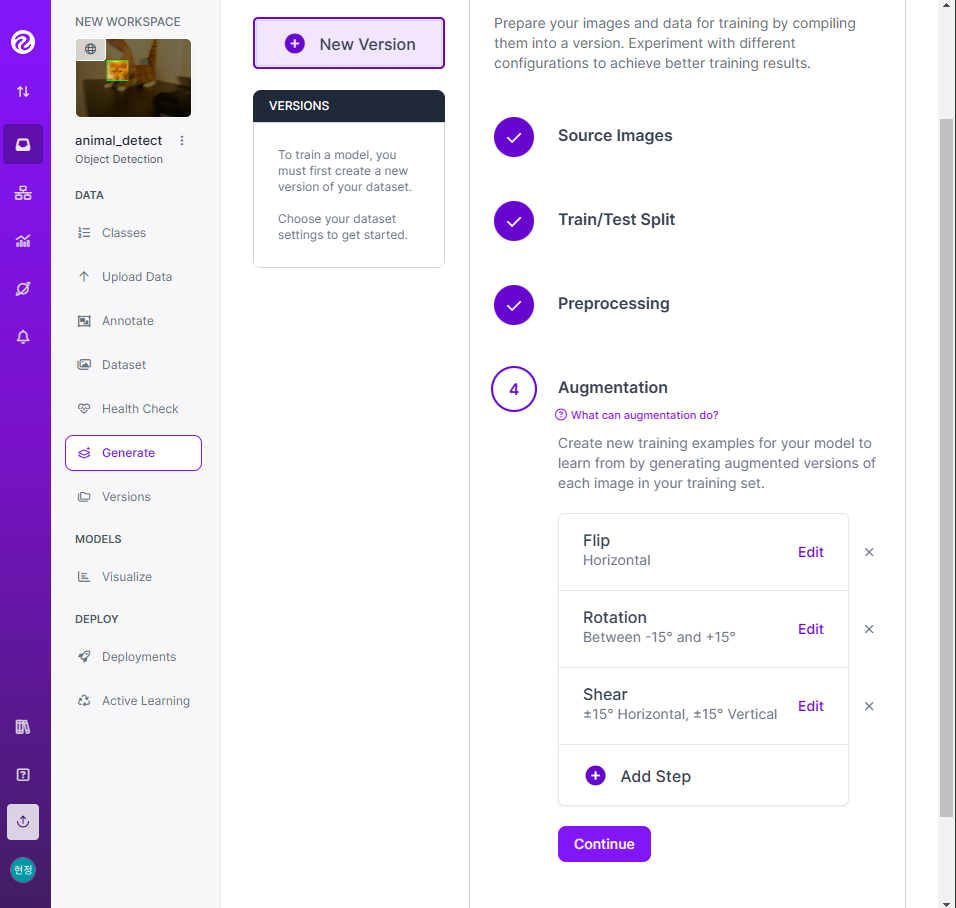
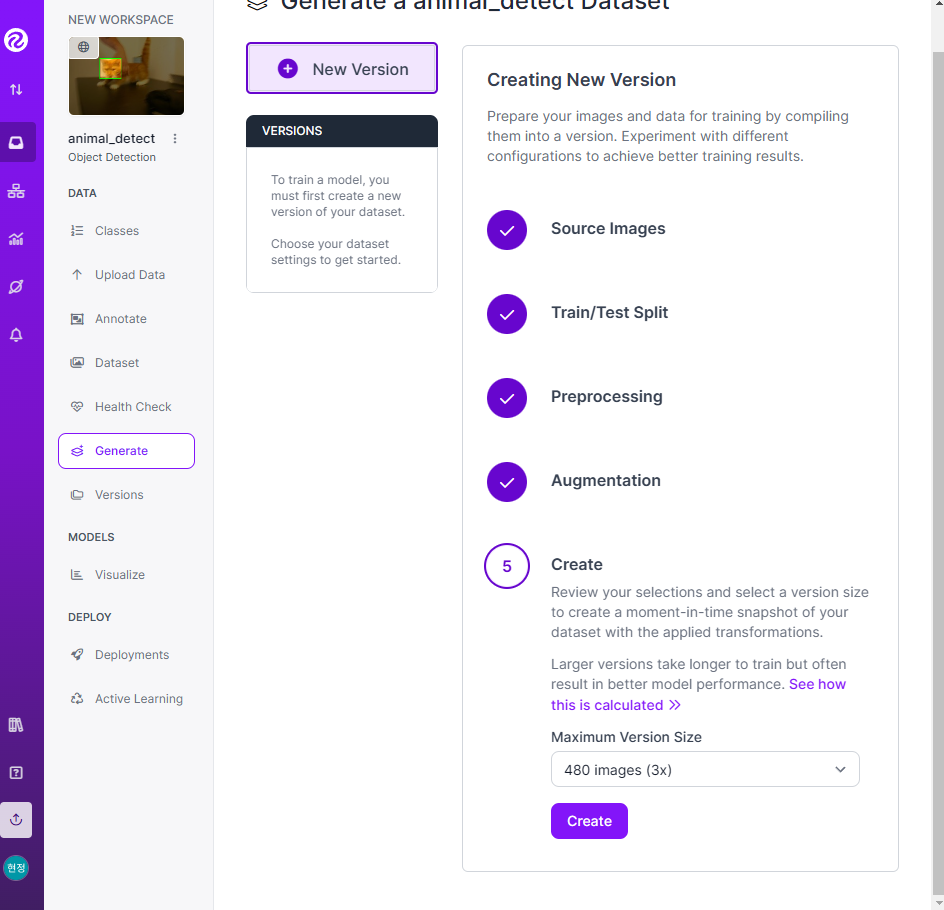
- 라벨링 작업

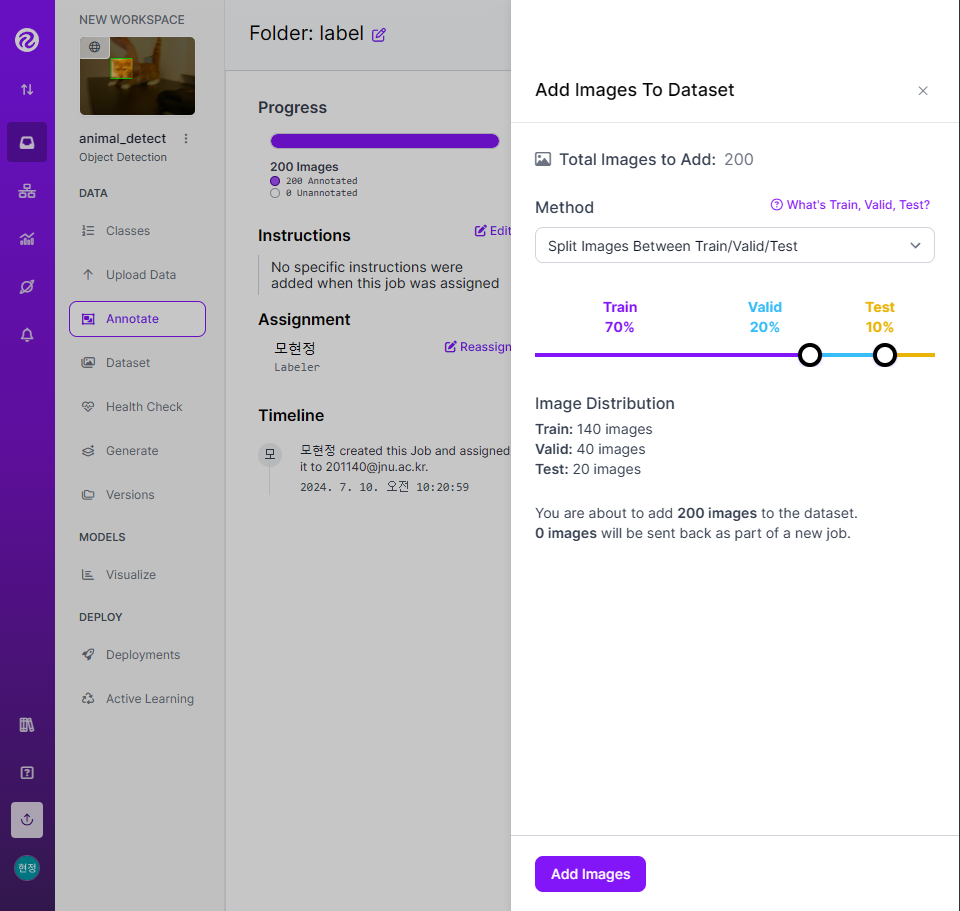
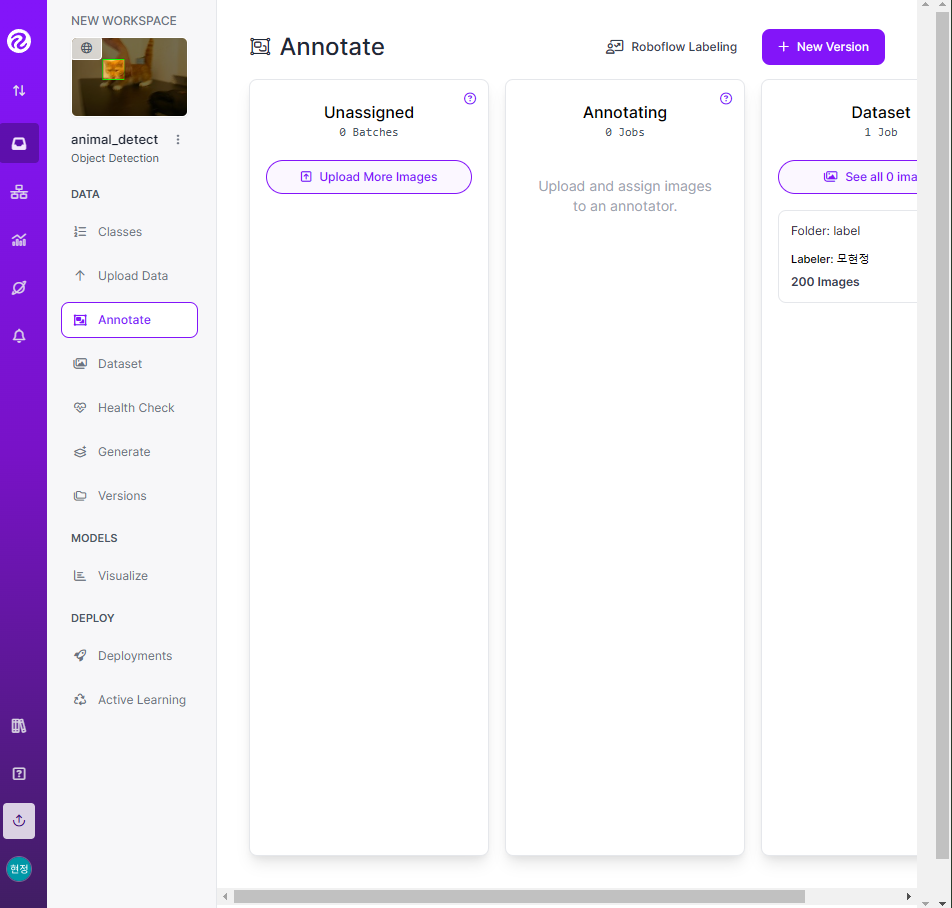
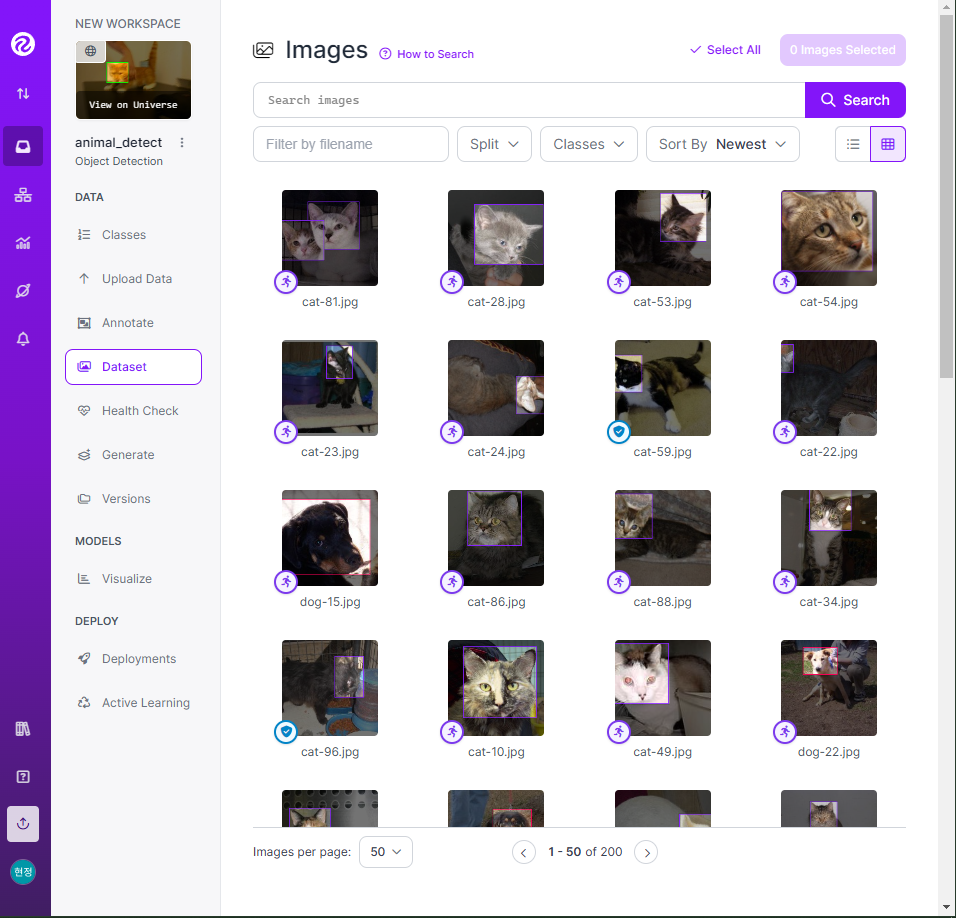
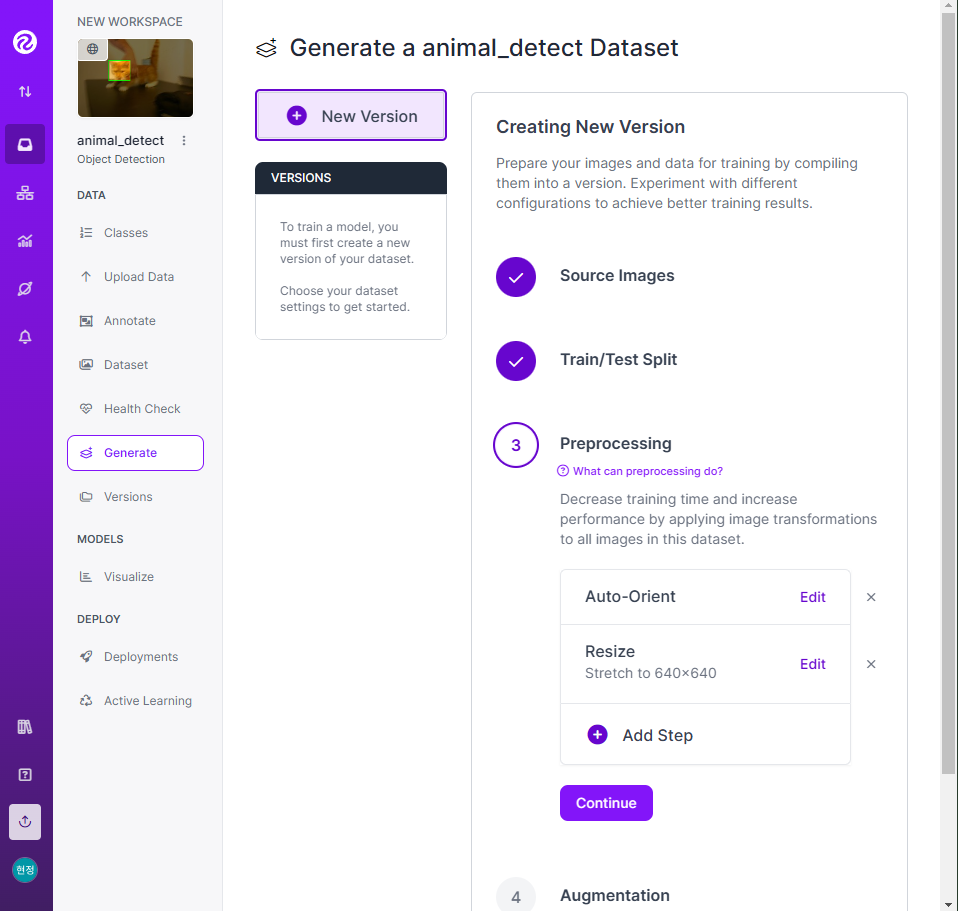
- 📌 구글 드라이브 연동
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/MyDrive/Colab Notebooks/Deep Learning
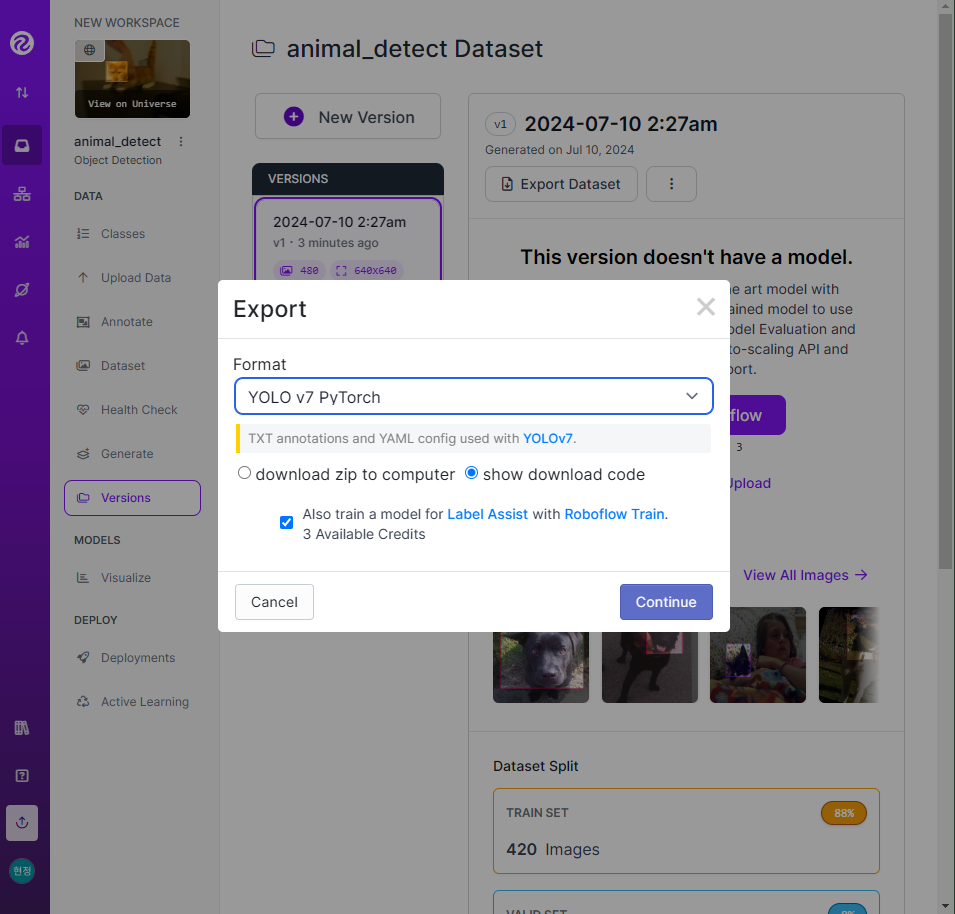
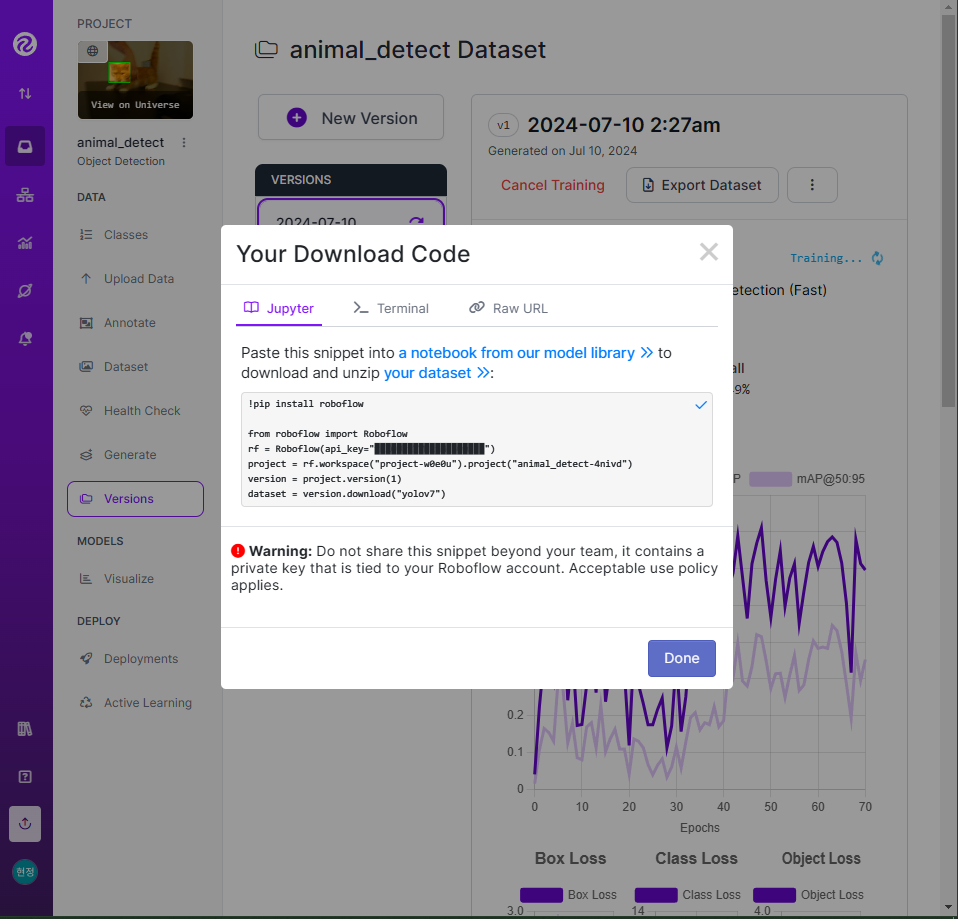
- 📌 roboflow에서 라벨링한 데이터를 가져오기
!pip install roboflow
from roboflow import Roboflow
# API Key
rf = Roboflow(api_key="API Key")
# 작업명, 프로젝트명
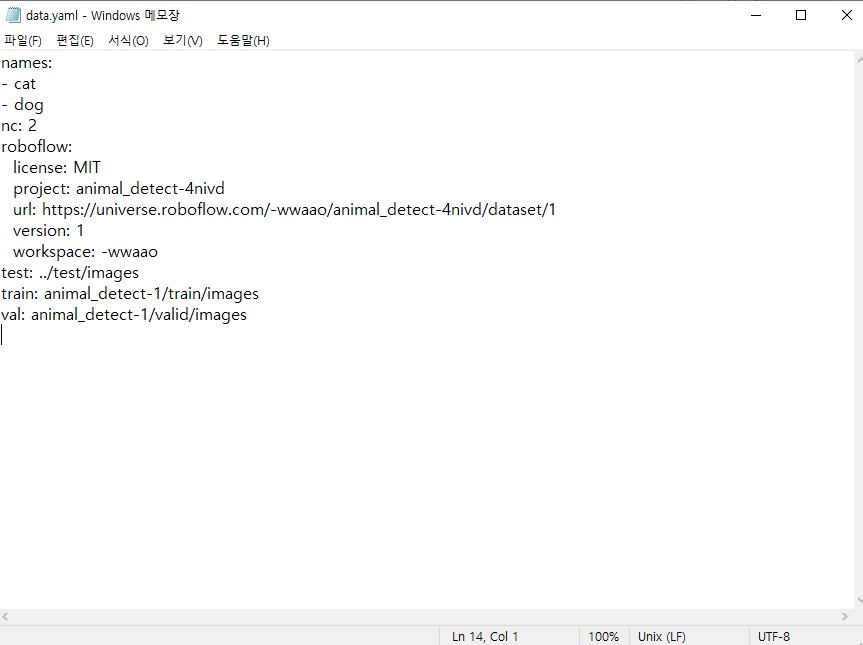
project = rf.workspace("project-w0e0u").project("animal_detect-4nivd")
# 가져올 버전
version = project.version(1)
# 대상 모델
dataset = version.download("yolov7")
- 📌 YoloV7 다운로드
import os.path
if not os.path.exists("yolov7.pt"):
!git clone https://github.com/WongKinYiu/yolov7.git
%cd yolov7
- 📌 관련 라이브러 설치
!pip install -r requirements.txt
- 📌 이전에 훈련된 모델을 다운로드(전이학습)
# 필요한 모델 사용 (s, m, l ...) - 큰 모델을 사용하면 정확도는 우수하지만 속도가 느리고 메모리도 많이 차지함
!wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7_training.pt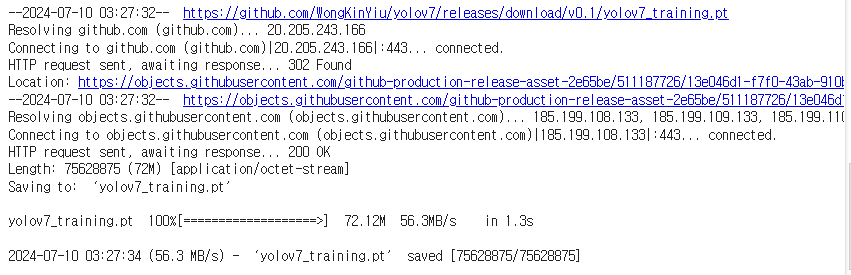
- 📌 훈련
%cd ..
- 📌 device : GPU 번호
- 📌 data : 사용할 데이터 (yaml 파일명)
- 📌 weights : 사용할 학습된 yolo 모델명
- 📌 출력 결과
- last.pt : 가장 마지막에 학습된 모델
- best.pt : 가장 성능이 우수한 모델
!python ./yolov7/train.py --batch 16 --epochs 20 --device 0 \
--data ./animal_detect-1/data.yaml --weights ./yolov7/yolov7_training.pt
- 📌 학습된 모델 평가하기
!python ./yolov7/test.py --batch 16 --weights ./runs/train/exp/weights/best.pt \
--data ./animal_detect-1/data.yaml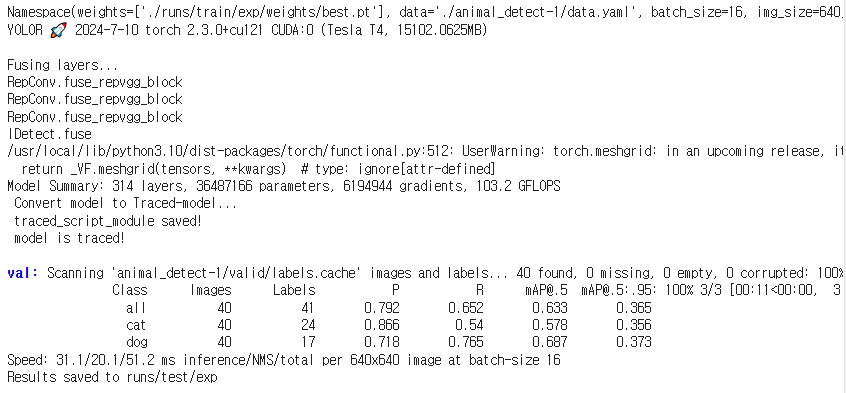
- 📌 객체 탐지 및 인식
- source 값에 영상 파일 또는 카메라 번호(0, ...)을 입력해서 영상이나 카메라 입력을 사용할 수 있다
!python ./yolov7/detect.py --weights ./runs/train/exp/weights/best.pt \
--source ./animal_detect-1/test/images
import glob
import matplotlib.pyplot as plt
i = 0
limit = 20
for imageName in glob.glob("./runs/detect/exp/*.jpg"):
if i < limit:
display(plt.imread(imageName))
print("\n")
i += 1
!python ./yolov7/detect.py --weights ./runs/train/exp/weights/best.pt \
--source ./data/cat.mp4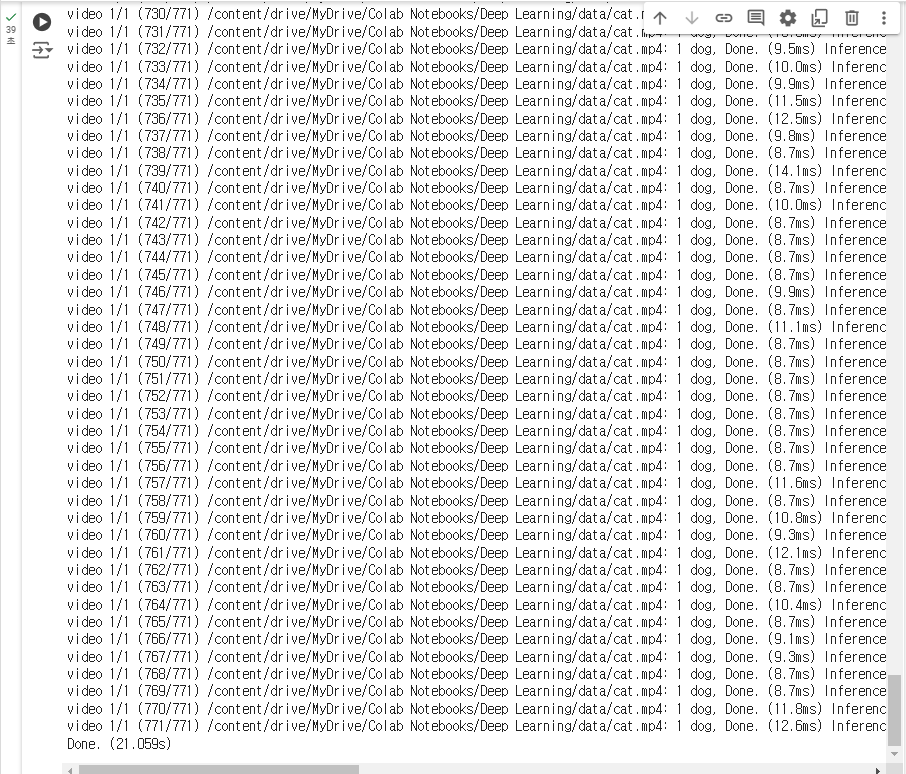

# 카메라인 경우
!python ./yolov7/detect.py --weights ./runs/train/exp/weights/best.pt --source 0# 유튜브
!python ./yolov7/detect.py --weights ./runs/train/exp/weights/best.pt --source # 유튜브 URL 주소
'Deep Learning' 카테고리의 다른 글
| 얼굴 표정 인식 (0) | 2024.07.12 |
|---|---|
| OpenCV_021_얼굴검출_스켈레톤(MediaPipe) (0) | 2024.07.11 |
| CNN_개_고양이_이진분류실습(모델링) (0) | 2024.07.09 |
| CNN 개_고양이_이진분류 실습(데이터 만들기) (0) | 2024.07.08 |
| CNN(Convolutional Neural Network) (0) | 2024.07.05 |